Table of Contents
- What data lineage actually is
- Why AI systems demand better lineage
- How data lineage compares to provenance and cataloguing
- Key capabilities and implementation techniques
- Real limitations and implementation challenges
- Choosing the right lineage approach for your architecture
- FAQ
Studies indicate poor data quality costs companies $12.9 million annually on average, while regulatory fines for data mishandling exceeded $4 billion globally in the past five years. When your churn prediction model suddenly flags loyal customers as high-risk, you need more than clean data. You need to trace whether the problem stems from a pipeline change three systems upstream, a shifted business rule, or corrupted source data.
Data lineage is the ability to trace how data flows, transforms, and impacts business outcomes across your entire organization, from source systems through transformations to the dashboards and AI models that depend on it. Think of it as the nervous system of your data architecture. Unlike traditional analytics where humans review dashboards before making decisions, AI systems operate autonomously. When they fail, lineage provides the diagnostic trail you need to identify root causes quickly.
This matters more in 2025 because the EU AI Act, effective August 2024, obliges companies deploying high-risk AI to document data origins, transformations, and quality metrics, with failure triggering fines up to $39.82 million or 7% of global turnover. Data lineage has evolved from a nice-to-have technical feature into a regulatory requirement and business strategy.
Data lineage is the process of tracking and documenting the flow of data from its origin to its final destination, capturing every transformation, movement, and dependency along the way. It answers fundamental questions about your data: where it comes from, how it changes, where it moves over time, and which systems depend on it. 95% of companies using data lineage meet regulatory requirements like GDPR, and lineage tools have helped improve decision-making quality by 15-20% with more reliable data foundations.
What data lineage actually is
Data lineage refers to the tracking of data as it moves through the various stages of a system or process, from its origin or source to its final destination. It provides a visual representation of the data’s lifecycle, including where it comes from, how it transforms, and where it goes.
Consider a retail business tracking sales data. Data lineage illustrates how sales figures are collected from point-of-sale systems, processed through analytics platforms, aggregated with inventory data, transformed through business logic that calculates margins and trends, and ultimately reported in financial dashboards. When revenue numbers look wrong, lineage shows you exactly which transformation introduced the error.
Data lineage facilitates the ability to replay specific segments or inputs of the dataflow, which can be used in debugging or regenerating lost outputs. This becomes critical in AI systems where reproducing model training runs or understanding why a prediction changed requires tracing back through multiple data transformations.
The core components of data lineage include data capture sources (where data originates), transformation processes (how data changes), metadata management (information about data characteristics and relationships), and visualization layers (graphical representations of data flows). Modern automated lineage tools handle these components programmatically, capturing metadata as data moves through pipelines without manual documentation.
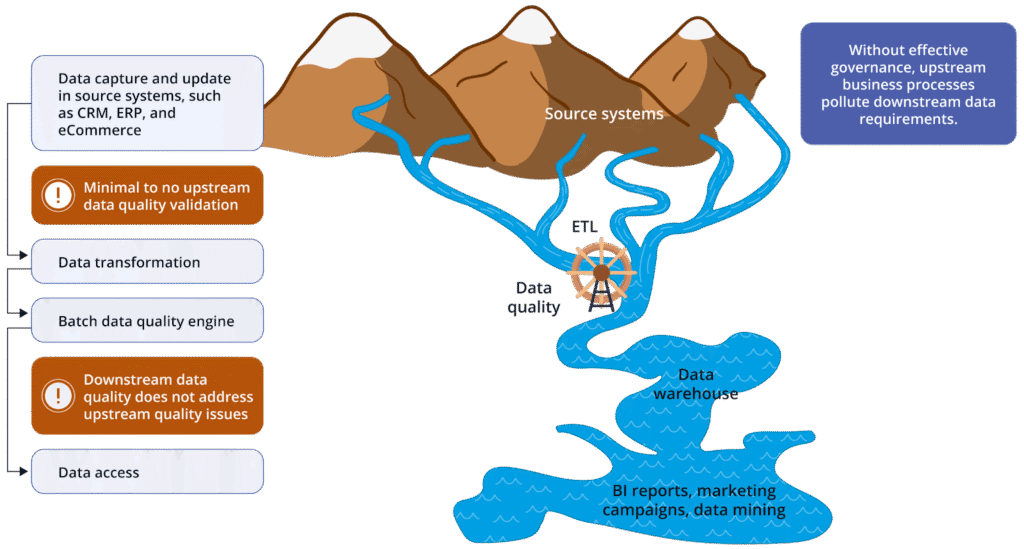
Complete data lineage maps every transformation from source systems to business outcomes
Column-level lineage tracks data at the most granular level, showing how specific columns in source tables map to columns in target tables through each transformation. This granularity matters when you need to understand precisely which input fields affect a specific calculation or when tracking sensitive data like personally identifiable information through your entire data estate.
Why AI systems demand better lineage
AI systems operate autonomously, unlike traditional analytics where a human reviews a dashboard before making a decision. When your model’s accuracy suddenly drops, you need to quickly trace whether the issue stems from a pipeline change, a data quality problem, or a shift in business logic upstream.
AI models require rich context, not just clean data. They need to understand that ‘monthly recurring revenue’ means something specific to your business, with particular calculation rules and exclusions. Context-rich lineage ensures that models operate with the right business understanding, not just technically correct data structures.
AI-ready data lineage is lineage metadata that is complete, granular, continuously updated, and accessible to both humans and AI systems. It provides the context AI agents need to understand, trace, and act on data across your ecosystem. This enables natural language interfaces where you can ask questions like “Where is this customer’s data stored?” or “What data points were used to reject this loan application?” and receive accurate, traceable answers.
The shift toward AI has made lineage exponentially more important. A subtle change in how you define “active user” can completely alter model behavior. Without proper lineage, you have no way to trace that impact or restore trust. Ataccama’s recent 2025 data trust report found that only one-third of more than 300 respondents reported success in developing and deploying AI applications, with data quality and traceability issues being major blockers.
Generative AI is reshaping lineage itself. Gen AI has emerged as a transformative force in metadata engineering, bringing intelligence, scale, and adaptability to environments once mired in manual effort. Gen AI-powered lineage tools can parse and understand any codebase (SQL, Python, Scala), automatically detect transformations, build semantic graphs representing datasets and lineage, and generate human-readable summaries for governance and audits.
Show Image AI systems require granular lineage to trace model inputs and transformations
How data lineage compares to provenance and cataloging
The terms data lineage, data provenance, and data cataloging often get used interchangeably, but they serve distinct purposes in data management.
Data provenance is concerned with just the historical record of the source of data, while data lineage is concerned with the full evolution of data throughout the pipeline, from the moment it’s ingested through every transformation. Provenance focuses on the origin and authenticity of data, providing the historical context and audit trail. Lineage tracks the complete flow and transformation.
Data lineage tracks the flow and transformation of data through systems, showing where data originates, how it moves, and how it’s altered. Data provenance emphasizes the origin and authenticity of the data, ensuring its source and history are verifiable. In practice, provenance is useful for validating and auditing data sources, while lineage is useful for optimizing and troubleshooting data pipelines.
In industry usage, data lineage is closely related to provenance: lineage typically denotes the end-to-end flow of datasets and transformations across systems (from sources through processing to outputs), while provenance emphasizes derivations and attribution of specific data items. The two are complementary.
Data catalogs serve a different function entirely. A data catalog is a tool that organizes and centralizes metadata, helping users discover, access, and manage data efficiently. Data lineage, on the other hand, tracks the origins, transformations, and destinations of data to ensure traceability and transparency. While the catalog answers “what” data is available, lineage explains “where” the data comes from and “how” it evolves.
According to IDG & Matillion, most businesses handle data from between 400 and 1,000 separate sources. Both data catalogs and lineage are indispensable for managing this complexity. They work synergistically: catalogs help users discover data assets while lineage helps them understand data dependencies and impact.
The practical difference matters when you’re troubleshooting. If your quarterly revenue report shows unexpected numbers, lineage helps you trace back through every calculation and transformation to find where things went wrong. Provenance tells you whether the source data itself is trustworthy and properly authenticated. The catalog helps you find related datasets and understand what each field means.
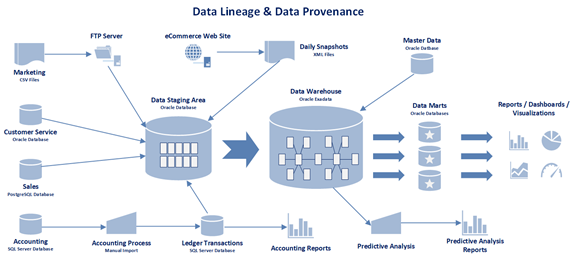
Data lineage, provenance, and cataloging serve complementary but distinct roles
Key capabilities and implementation techniques
Modern data lineage tools deliver several critical capabilities that distinguish robust implementations from basic metadata tracking.
Automated metadata collection forms the foundation. Modern automated data lineage solutions efficiently track data flows, ensuring accuracy and reducing the effort required to maintain visibility across complex systems. Tools automatically parse SQL queries, ETL scripts, orchestration workflows, and application code to extract lineage information without manual documentation.
Column-level granularity provides the precision needed for serious governance work. Instead of knowing that Table A feeds Table B, you know that column customer_id in Table A maps to user_identifier in Table B through a specific transformation. Without precision at the column level, data lineage becomes more of a visual map than a trustworthy control layer.
Impact analysis lets you simulate changes before implementing them. When you need to rename a field or modify a calculation, impact analysis shows every downstream report, dashboard, and model that will be affected. Gartner’s analysts describe lineage as critical “to perform rapid root cause analysis of data quality issues and impact analysis of remediation”.
OpenLineage standardization has emerged as the preferred approach for interoperability. OpenLineage defines a generic model of run, job, and dataset entities identified using consistent naming strategies. The core lineage model is extensible by defining specific facets to enrich those entities. This open standard enables lineage collection across heterogeneous tools like Airflow, Spark, dbt, and Flink without vendor lock-in.
At the core of OpenLineage is a standard API for capturing lineage events. Pipeline components like schedulers, warehouses, analysis tools, and SQL engines can use this API to send data about runs, jobs, and datasets to a compatible OpenLineage backend for further study. Major cloud providers including Google Cloud Platform now support OpenLineage ingestion.
Implementation techniques fall into several categories. Pattern-based lineage scans SQL queries, ETL code, and transformation logic to infer data flows through static analysis. Event-based lineage captures metadata in real-time as jobs execute, recording actual data movements rather than inferred relationships. Catalog integration enriches lineage with business context from data catalogs, adding semantic meaning and ownership information.
For best practices on implementing comprehensive data lineage, consulting resources like data lineage best practices guides can provide detailed frameworks and real-world implementation strategies.
Self-contained lineage is embedded directly into the data platform or pipeline tool itself. Systems like dbt or Apache Beam generate and expose lineage metadata as part of their native operation. This approach makes integration easier and lineage more complete since the tools already understand their own data flows.
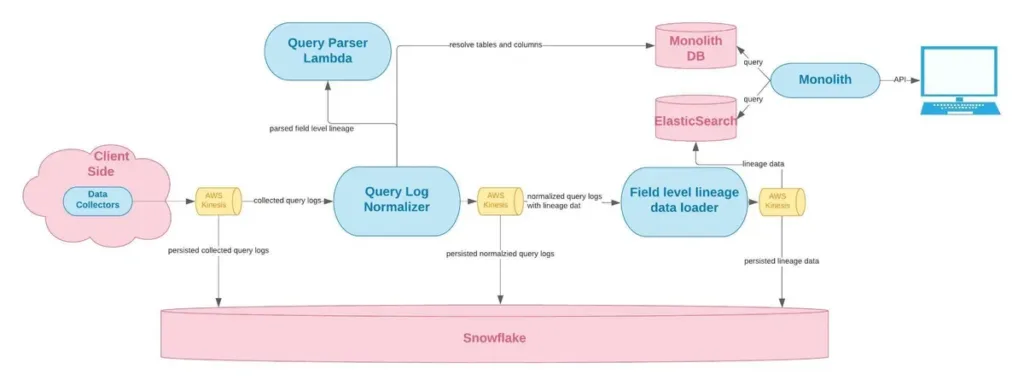
Column-level lineage provides the granularity needed for compliance and troubleshooting
Real limitations and implementation challenges
Data lineage delivers clear benefits, but implementing it successfully requires navigating several significant obstacles that organizations frequently underestimate.
Modern data stacks combine dozens of different tools. You might have traditional databases, cloud warehouses, streaming platforms, ETL pipelines, APIs, and BI tools all working together. Capturing lineage across these heterogeneous environments proves difficult because each tool speaks its own language. Integration becomes the main hurdle. Some tools expose rich metadata APIs while others barely document their internals. Legacy applications often lack any metadata capabilities at all.
The result is gaps in your lineage map where certain data flows remain invisible. You know data moves from point A to point B, but the specifics stay hidden in black boxes. Complications arise with nested transformations, dynamic SQL, or operations that obscure direct relationships between source and target columns (e.g., pivoting or window functions). Tools must not only parse the logic but also understand execution context to build precise mappings.
Scalability challenges compound as data volumes grow. A number of challenges must be addressed, including the scalability of the lineage store, the fault tolerance of the lineage store, the accurate capture of lineage for black box operators, and numerous other considerations. The overall number of operators executing at any time in a cluster can range from hundreds to thousands depending on cluster size. Lineage capture for these systems must be able to scale to both large volumes of data and numerous operators to avoid becoming a bottleneck.
Lineage documentation ages poorly. Without automation, your carefully mapped data flows become outdated within weeks as pipelines evolve and schemas change. Manual updates can’t keep pace with modern development cycles where changes deploy daily. This creates a trust problem. Once engineers discover outdated lineage information, they stop relying on it entirely.
Resistance emerges when lineage feels like overhead rather than a tool that helps daily work. If engineers see lineage as extra bureaucracy instead of debugging assistance, adoption fails. The cultural shift requires demonstrating immediate value and reducing friction in the collection process.
Organizational silos compound these cultural challenges. Data engineering owns the pipelines, analytics owns the reports, and IT owns the infrastructure. Each group has different priorities and toolsets. Getting everyone aligned on lineage standards and practices requires political capital and sustained executive support. Without this alignment, lineage efforts fragment into disconnected initiatives that never achieve critical mass.
Traditional data lineage tools often do not deliver sufficient ROI beyond migration projects. As a result, business users often view standalone data lineage solutions as low-value investments, leading organizations to seek more integrated approaches. The future lies in embedding lineage within broader data governance and quality ecosystems rather than treating it as a standalone tool.
Cost considerations can’t be ignored. Costs can escalate due to the need for specialized software, training personnel, and ongoing maintenance. Budget overruns or resource shortages during implementation phases indicate financial challenges that organizations must plan for upfront.
Real-time systems present unique challenges. It’s remarkably difficult to tell how data got into its current state when you’re dealing with streaming architectures, and this creates nightmares for troubleshooting, data quality, and compliance. Traditional batch-oriented lineage tools struggle with the continuous, event-driven nature of streaming pipelines.
Organizations face multiple technical and organizational hurdles when implementing lineage
Choosing the right lineage approach for your architecture
Selecting the appropriate data lineage solution requires understanding which tools can scale with your environment, plug into your workflows, and deliver clarity across your data landscape.
For modern cloud-native stacks, enterprise platforms like Collibra, Alation, and Atlan dominate. Collibra remains a dominant force in enterprise data governance and lineage, known for its deep integration with existing IT ecosystems. It provides a rich cataloging system, metadata management, and end-to-end visibility into data movement across hybrid environments. These platforms work well for highly regulated sectors like financial services and insurance.
Atlan is a rising star in the modern data stack, often referred to as a “data collaboration workspace.” Its lineage capabilities are intuitive, focusing on transparency and usability for data teams. The platform connects to major BI, warehouse, and orchestration systems, offering near-real-time lineage mapping. Startups and mid-sized enterprises especially value it for its balance of affordability, simplicity, and speed of deployment.
For complex legacy environments, specialized tools like MANTA and IBM Metadata Manager excel. MANTA specializes in automated, detailed lineage mapping, often considered the “engine” behind lineage features in other platforms. It provides technical depth by scanning code, ETL scripts, and database logic to create highly granular lineage views. This makes it especially powerful for enterprises with complex legacy systems.
For open-source and custom implementations, DataHub, Apache Atlas, and OpenLineage provide flexible foundations. DataHub uses machine learning to suggest owners, enrich metadata, and rank search results, bringing practical AI into metadata discovery and curation. However, complex deployments require Kubernetes and Kafka-based setup, requiring DevOps investment.
Open-source tools are a great starting point. They help surface data flows, trace transformations, and prototype lineage across cloud-native stacks. But as enterprise needs scale, their limitations start to show. Across systems like SAP, Salesforce, Snowflake, and BigQuery, lineage becomes fragmented. Manual diagrams, disconnected pipelines, and missing dependencies are common.
When evaluating tools, look for these essential capabilities: visual data mapping with interactive flowcharts or directed graphs, predictive impact analysis allowing you to simulate changes and predict downstream effects, seamless integration with existing systems including ETL platforms and BI tools, and collaboration features supporting communication among data users and stakeholders.
Gartner’s report emphasizes lineage as an “emerging technology” and sees data lineage as part of a large category it calls “active metadata management”. Any data lineage solution must have close integration with metadata solutions to enable effective lineage tracking. In Gartner’s view, data lineage is a foundational technology for any data-mature enterprise.
Key features any data lineage solution should include: column-level lineage for granular visibility into how data and its characteristics change over time, connectivity to a broad array of third-party systems for collecting metadata and lineage information, automated lineage tracking providing clarity on data origins and transformations, and real-time or near-real-time updates keeping metadata continuously aligned with production.
Software solutions accounted for 57.1% of revenue in 2024, anchoring the data governance market with capabilities that automate policy enforcement, metadata harvesting, and lineage visualization. AI-driven classification and anomaly detection are now baseline features, helping organizations comply with regulatory requirements in real time.
The decision often comes down to your architecture complexity, regulatory requirements, budget constraints, and internal technical expertise. Organizations with straightforward cloud-native stacks can often succeed with integrated catalog solutions like Atlan or Alation. Those with complex multi-cloud environments spanning legacy and modern systems may need specialized tools like Informatica or MANTA. Teams with strong engineering capabilities and desire for customization should evaluate open-source options like DataHub or building on OpenLineage standards.
Conclusion
Data lineage has evolved from a technical nice-to-have into a business and regulatory imperative. Organizations that implement comprehensive, automated lineage gain faster root cause analysis, better AI model reliability, proactive compliance, and increased trust in data-driven decisions. Those that don’t risk regulatory fines, data quality issues, and AI systems that fail in opaque ways.
The winners in 2025 are organizations that embed lineage into broader data governance ecosystems rather than treating it as a standalone tool. They automate metadata collection, achieve column-level granularity, integrate with existing workflows, and provide business context alongside technical details. They recognize that lineage isn’t just about tracking data flows, it’s about ensuring data is accurate, reliable, and trusted for all users across the enterprise.
As AI systems become more autonomous and regulatory requirements grow stricter, the question isn’t whether to implement data lineage but how quickly you can do it effectively. Start with your most critical data flows, automate aggressively, and integrate lineage into daily workflows rather than treating it as documentation overhead. The organizations that master lineage today will be the ones whose AI systems and data operations remain trustworthy tomorrow.
FAQ
Q: How much does data lineage software typically cost?
A: Data lineage costs vary widely based on deployment model and features. Enterprise platforms like Collibra and Informatica typically charge $50,000 to $500,000+ annually based on data volume and user count. Mid-market tools like Atlan and OvalEdge range from $20,000 to $100,000 annually. Open-source options like DataHub and Apache Atlas are free but require significant engineering resources for deployment and maintenance, often costing $100,000+ in internal labor annually.
Q: Is data lineage better than data cataloging for governance?
A: Data lineage and data cataloging are complementary, not competing solutions. Catalogs help users discover what data exists and understand its business meaning. Lineage shows how that data moves, transforms, and impacts downstream systems. For effective governance, you need both: catalogs provide the “what” and “why” while lineage provides the “where” and “how.” Modern platforms increasingly integrate both capabilities.
Q: Can data lineage work with legacy systems?
A: Yes, but with challenges. Modern lineage tools can extract metadata from legacy databases, mainframe systems, and older ETL platforms through database log mining, query parsing, and custom connectors. However, legacy systems often lack APIs and emit inconsistent metadata. Tools like MANTA and Informatica specialize in parsing legacy code and database logic. Expect to invest significant effort in custom connectors and metadata bridges for comprehensive legacy coverage.
Q: How long does it take to implement data lineage?
A: Implementation timelines range from weeks to months depending on environment complexity. Basic lineage for a single cloud data warehouse using integrated catalog tools can deploy in 2-4 weeks. Comprehensive enterprise lineage spanning multiple clouds, legacy systems, and hundreds of data sources typically takes 3-6 months for initial deployment and 12-18 months to reach full maturity. Organizations should plan for iterative rollouts starting with high-priority data flows rather than attempting complete coverage immediately.
Q: What’s the difference between automatic and manual data lineage?
A: Automatic data lineage uses tools to scan code, parse queries, and infer data flows programmatically without human intervention. Manual lineage requires data engineers to document flows using spreadsheets or diagrams. Automatic lineage scales to modern data volumes and stays current as pipelines change, while manual lineage becomes outdated within weeks and can’t handle enterprise-scale complexity. Organizations using manual approaches report spending 20-40 hours per month on documentation versus 2-5 hours for automated validation and exceptions.
Sources
- BetaNews: Why data lineage is a business strategy – Interview discussing data lineage as the nervous system of data architecture and its importance for AI systems
- OvalEdge: Top 12 AI-Powered Open-Source Data Lineage Tools – Comprehensive evaluation of open-source lineage solutions and their AI capabilities
- Atlan: AI-Ready Data Lineage – Definition and requirements for AI-ready data lineage with natural language interfaces
- Velotix: 10 Top Data Lineage Tools in 2025 – Overview of automated lineage solutions and essential capabilities
- SCIKIQ: Top 10 Data Lineage Tools Transforming AI – Analysis of lineage tools’ impact on trustworthy AI and compliance
- Medium: Lineage at Scale with Gen AI – Technical deep dive on Gen AI-powered metadata engineering
- Atlan: Data Lineage vs Data Provenance – Detailed comparison of lineage and provenance concepts with use cases
- Secoda: Key Distinctions Between Lineage and Provenance – Analysis of how lineage and provenance differ in scope and application
- ZenData: Data Provenance vs Data Lineage – Explanation of provenance focusing on historical record and authenticity
- Atlan: Data Catalog vs Data Lineage – How catalogs and lineage work together for data management
- Monte Carlo: Data Provenance vs Data Lineage Differences – Practical comparison with use cases and implementation guidance
- Wikipedia: Data Lineage – Technical overview including relationship to data provenance
- Monte Carlo: The Ultimate Guide to Data Lineage – Comprehensive guide covering challenges and best practices
- Prophecy: Data Lineage is Broken – Analysis of common lineage implementation failures and solutions
- Seemore Data: Data Lineage Examples and Best Practices – Technical implementation techniques and versioning approaches
- Secoda: Challenges of Data Lineage Implementation – Detailed breakdown of scalability and organizational challenges
- Hevo: Data Lineage Challenges – Real-world case studies including Panasonic and Air France
- Gable: Practical Solutions for Complex Data Lineage Challenges – Strategic approaches using Ashby’s Law for complexity management
- Select Star: Complete Guide to Data Lineage – Implementation steps and automated column-level lineage
- Improving: Effective Data Lineage Strategies for Real-Time Systems – Technical strategies for streaming architectures and trace ID propagation
- Mordor Intelligence: Data Governance Market Analysis – Market size data, regulatory impacts, and EU AI Act compliance requirements
- Ataccama: Evolution of Data Lineage – Analysis of ROI challenges and integration trends
- Decube: Driving ROI with Data Lineage – ROI statistics showing 95% regulatory compliance and 15-20% decision improvement
- Atlan: Gartner on Data Lineage – Gartner’s perspective on lineage as foundational technology
- DATAVERSITY: Data Management Trends in 2025 – Industry trends with 80% of firms prioritizing metadata management
- OpenLineage GitHub – Open standard specification for lineage metadata collection
- OpenLineage Official Site – Overview of OpenLineage API and architecture
- Google Cloud: OpenLineage Integration – Documentation on importing OpenLineage events to GCP
- Google Open Source: GCP Lineage Producer Library – Implementation details for OpenLineage integration with GCP
- OvalEdge: Top 25 Data Lineage Tools – Comprehensive comparison of enterprise and open-source lineage platforms