Your model just made a decision that cost someone money. An auditor asks: "Show me exactly which data influenced this outcome. Walk me through every transformation. Prove the data was lawfully sourced."
If you're running on most production ML stacks today, you have roughly 90 seconds before the conversation gets uncomfortable. Your feature pipelines are scattered across notebooks and DAGs. Training datasets are versioned by timestamp, not by content hash. Models live in registries with links to "the data" but no binding to specific records.
This is an architecture problem. And regulators have noticed.
What data lineage actually means (and what it doesn't)
In traditional analytics, lineage often stops at ETL graphs: table A feeds table B, which feeds a report. That model breaks down for AI systems.
AI introduces three structural complications:
- Training data may never appear in production requests, yet it directly shapes outcomes.
- Feature engineering is code defined, parameterized, and versioned independently of datasets.
- Outputs can re enter pipelines as labels, feedback signals, or retraining data.
For AI compliance, lineage must be end to end and lifecycle aware. This means tracking four distinct layers.
1. Source lineage
- Where did the raw data originate?
- What consent or lawful basis was documented?
- Which individuals' records does it contain?
2. Transformation lineage
- Every processing step matters: ingestion, cleaning, deduplication, joins, aggregation.
- Record which system, configuration, data version, timestamp, and output artifact resulted.
3. Training lineage
- Which dataset versions trained which model versions?
- What feature set and train–test split logic were used?
- What parameters and code version produced the trained artifact?
4. Decision lineage
When the model produced a prediction:
- Which feature values were used for that specific inference?
- Which feature definitions and versions produced those values?
- Which training data influenced the model weights that generated the output?
This is where most implementations fail. Training only traceability is insufficient once decisions affect individuals.
What lineage is not:
- Static diagrams updated quarterly
- Vendor dashboards with no exportable, immutable audit trail
- Metadata catalogs that cannot bind data → model → decision
If lineage cannot answer regulatory questions without manual reconstruction, it does not meet compliance standards.
What regulators now expect to hear
When an auditor asks: "Why did the system deny this loan application?"
"The model decided so" is regulator complaint material.
A defensible answer looks like this:
The application was declined because feature X exceeded threshold Y. Feature X was computed from records R1–R3, sourced from system S at timestamp T. Those records were collected under consent type C, lawful basis L, and were used to train model version M 2024-09.
That level of causal traceability is what regulators are now testing for in practice.
Regulatory pressure points converging on lineage
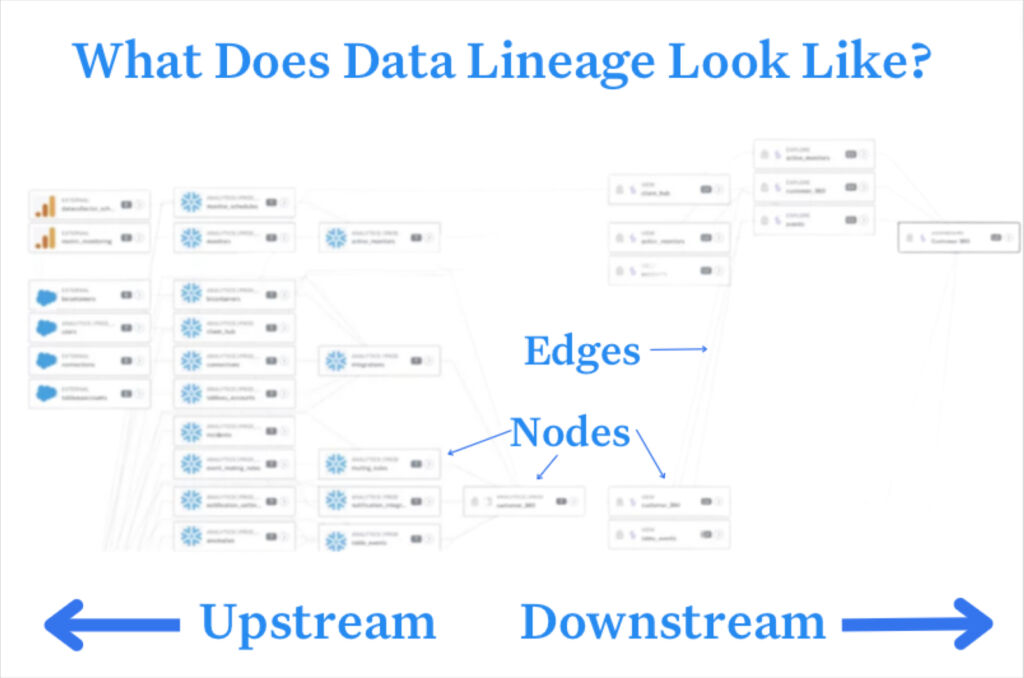

GDPR (Articles 5, 15, 22)
Under the General Data Protection Regulation, lineage is not optional.
Article 5 — Accountability
Without lineage, you cannot answer:
- Which datasets contain individual X's data?
- Which models were trained on it?
- Which decisions flowed from those models?
Article 15 — Right of access
A database export is insufficient. Auditors will ask: Show every transformation, every model training run, and every decision this data influenced.
Article 22 — Automated decision making
Regulators expect human reviewers to understand which data influenced a decision. Lineage is how that understanding is operationalized at scale.
EU AI Act (risk based obligations)
Under the EU AI Act, high risk systems must implement data governance, documentation, and traceability by design.
Article 14 explicitly requires that the use of personal data in training be traceable.
By August 2026, deploying high risk AI systems without demonstrable lineage constitutes a technical violation, with fines of up to 6% of global revenue.
ISO/IEC 42001 (AI management systems)
The International Organization for Standardization standard ISO/IEC 42001 requires:
- Documented control over training and test data
- Traceability from data → model → decision
- Reproducibility of results under audit conditions
Lineage is the mechanism that makes these requirements provable rather than aspirational.
Engineering architectures that enable compliant lineage
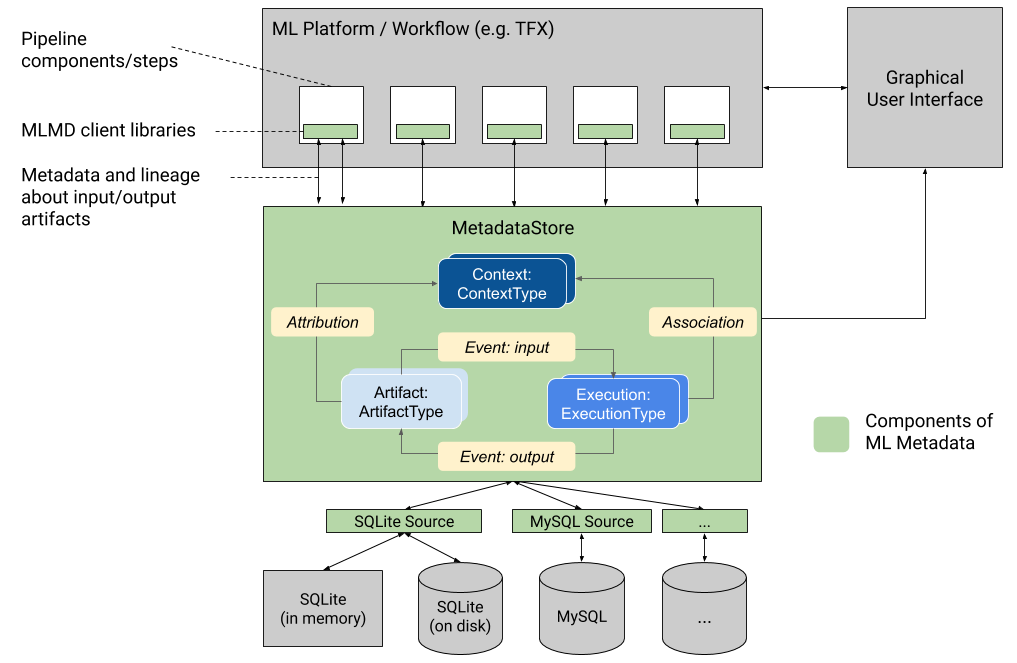


Event driven metadata capture
Lineage must be captured as pipelines execute, not reconstructed after the fact.
Each lifecycle stage emits structured metadata:
- Ingestion: dataset ID, record count, content hash, source system, timestamp
- Feature computation: feature ID, source dataset versions, output version
- Training: model ID, training dataset hash, feature set hash, metrics, timestamp
This forms an append only metadata stream. Storage overhead is modest approximately 500 bytes to 2 KB per event.
Common technologies: Apache Atlas, Kafka based custom emitters, AWS Glue Data Catalog.
Versioned artifacts everywhere
Datasets, features, and models must be versioned using content addressed identifiers (hash based), not human assigned names.
- Same data → same hash
- Different data → different hash
This property is cryptographically defensible under audit and eliminates ambiguity.
Feature store as a lineage choke point
If features are computed ad hoc in notebooks, lineage collapses immediately.
A feature store enforces:
- Centralized feature definitions
- Versioning
- Consistent reuse across models
Tools such as Tecton, Feast, and Databricks Feature Store typically require 6–12 weeks of upfront engineering effort.
Immutable logs and retention policies
Lineage metadata must be append only. Historical mutation signals loss of control.
Retention must align with regulation, not convenience:
- GDPR: 5–7 years after last interaction
- EU AI Act: model lifespan
- Financial services: 7–10 years
- Healthcare: 5–10 years
Cross system identity mapping
Lineage breaks when identifiers drift across systems.
Dataset 12345 in Snowflake and feature_dataset_001 in a feature store must be provably the same artifact. Stable organization wide IDs or explicit mapping tables are mandatory.
How lineage is used when auditors or incidents arrive


Pre audit validation
Select 10 random decisions from the past six months. For each, answer:
- Which records influenced it?
- What consent basis applied?
- What transformations were executed?
If this takes more than one hour per decision, your lineage is not audit ready.
Incident response and root cause analysis
When model performance drops 15% week over week, lineage enables a direct query:
What changed in training data or features?
Example outcome: Feature X switched from dataset Z to Y. Root cause identified in ~2 hours, not 3–5 days.
Change impact analysis before deployment
Before deploying a new model:
- Which downstream decisions will change?
- Which regulated processes are affected?
For high risk AI systems, this analysis is mandatory not best practice.
The honest assessment
Data lineage for AI compliance is not a feature you bolt on.
It is an architectural commitment that reshapes how AI systems are built, operated, and governed.
Organizations running high risk AI systems without lineage are operating with exposure they likely underestimate.
If your systems make decisions about real people, lineage is no longer optional.