AI governance is an engineering problem, not a policy deck.
For data teams, “AI governance” often arrives as a PDF from legal or compliance well intentioned, rarely actionable. In practice, governance is a set of engineering controls embedded in your ML lifecycle that determine what data can be used, how models are built, who approves deployment, and what evidence exists when regulators ask questions.
This guide focuses on implementation. It assumes you ship analytics, ML models, or GenAI features, and you want to reduce regulatory and operational risk without freezing delivery. The target outcome is boring but valuable: predictable approvals, traceable decisions, reproducible systems, and audits that take hours instead of weeks.
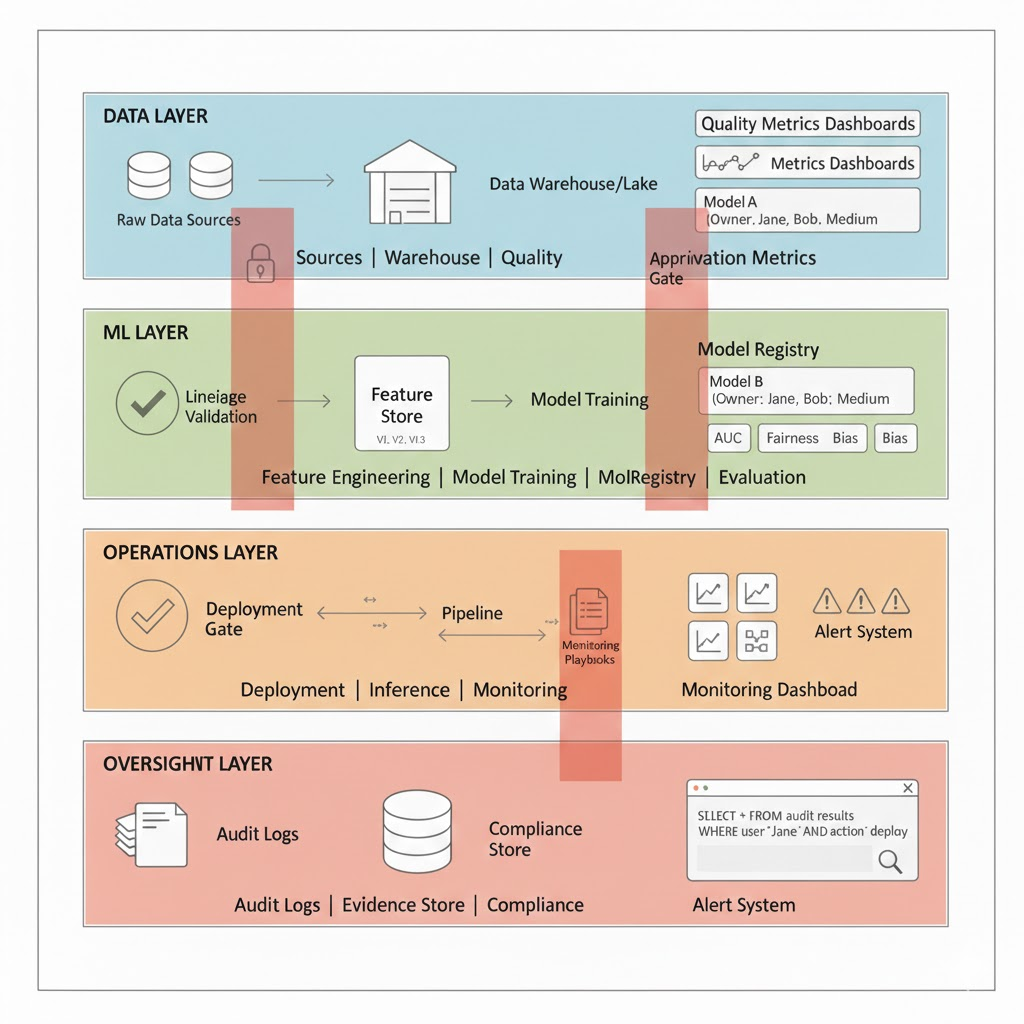
What “AI Governance” Means for Data Teams (In Concrete Terms)
At an execution level, AI governance answers six questions:
- Accountability: Who owns model outcomes in production?
- Data control: Where did training and inference data come from, and under what rights?
- Risk classification: Which models are high risk and why?
- Lifecycle control: How are models approved, monitored, retrained, and retired?
- Transparency: What evidence exists to explain decisions to auditors?
- Change management: What happens when data, code, or behavior drifts?
This is adjacent to but distinct from data governance. Traditional data governance focuses on datasets. AI governance extends that to behaviour over time, including non deterministic systems.
Regulatory pressure is the forcing function. Frameworks like GDPR, the EU AI Act, and ISO/IEC 42001 expect traceability, risk controls, and documented oversight. None of this is achievable retroactively.
Step 1: Define Ownership and Decision Rights (Before Tools)
Most governance failures start here: unclear ownership.
Minimum Viable Ownership Model
- Model Owner (Accountable): Senior IC or EM. Signs off on deployment and risk classification. Owns model performance in production.
- Data Steward (Responsible): Owns training/inference data sources, consent status, and retention. Validates data lineage before training.
- Risk/Compliance Reviewer (Consulted): Reviews high risk models only (see Step 2 for classification). Not a veto gate advisory.
- Platform/MLOps (Responsible): Enforces controls in CI/CD and runtime. Maintains model registry, monitoring, audit logs.
Critical: If you cannot name a single accountable owner per model, stop. You have a governance problem that tooling cannot fix.
Common mistake: Distributing accountability. “The team owns it” means nobody owns it.
Step 2: Classify AI Use Cases by Risk, Not by Model Type
A binary “AI vs. non AI” distinction is useless. Governance effort should scale with impact, not algorithm choice.
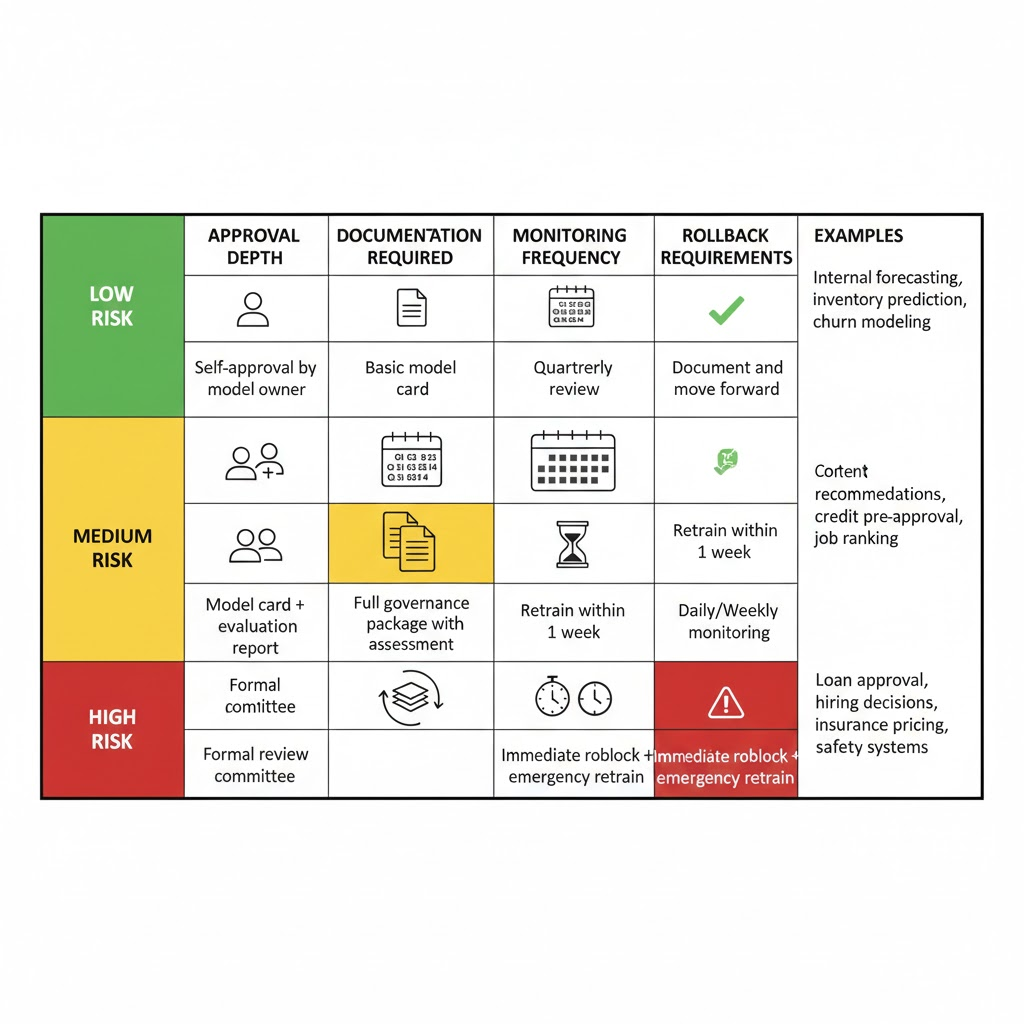
Practical Risk Taxonomy
- Low risk: Internal decision support, no user impact, reversible outcomes.
- Examples: Internal sales forecasting, inventory prediction, employee churn modeling
- Controls: Model owner sign off, basic documentation, annual review
- Medium risk: Customer facing recommendations, human in the loop approvals.
- Examples: Content recommendations, credit pre approval, job candidate ranking
- Controls: Peer review, evaluation metrics (AUC, coverage), quarterly monitoring
- High risk: Automated decisions affecting rights, finances, access, or safety.
- Examples: Loan approval, hiring decisions, insurance pricing, safety critical systems
- Controls: Formal review, bias assessment, continuous monitoring, weekly incident checks, audit logs
Tie this classification to gates:
- Approval depth (peer review vs. formal committee)
- Required documentation (data card vs. full governance package)
- Monitoring frequency (quarterly vs. daily)
- Retraining triggers and rollback requirements
Avoid over classifying. Teams that label everything “high risk” end up bypassing governance entirely.
Step 3: Make Data Lineage Non Optional
Data lineage is the backbone of AI governance. Without it, you cannot answer:
- Which models were trained on dataset X?
- Did personal data enter this feature store?
- Which systems are affected if a source is revoked or consent withdrawn?
For AI systems, lineage must cover:
- Source → transformation → feature → model → prediction
- Training vs. inference paths separately
- Versioned schemas and immutable snapshots
- Retention and deletion events
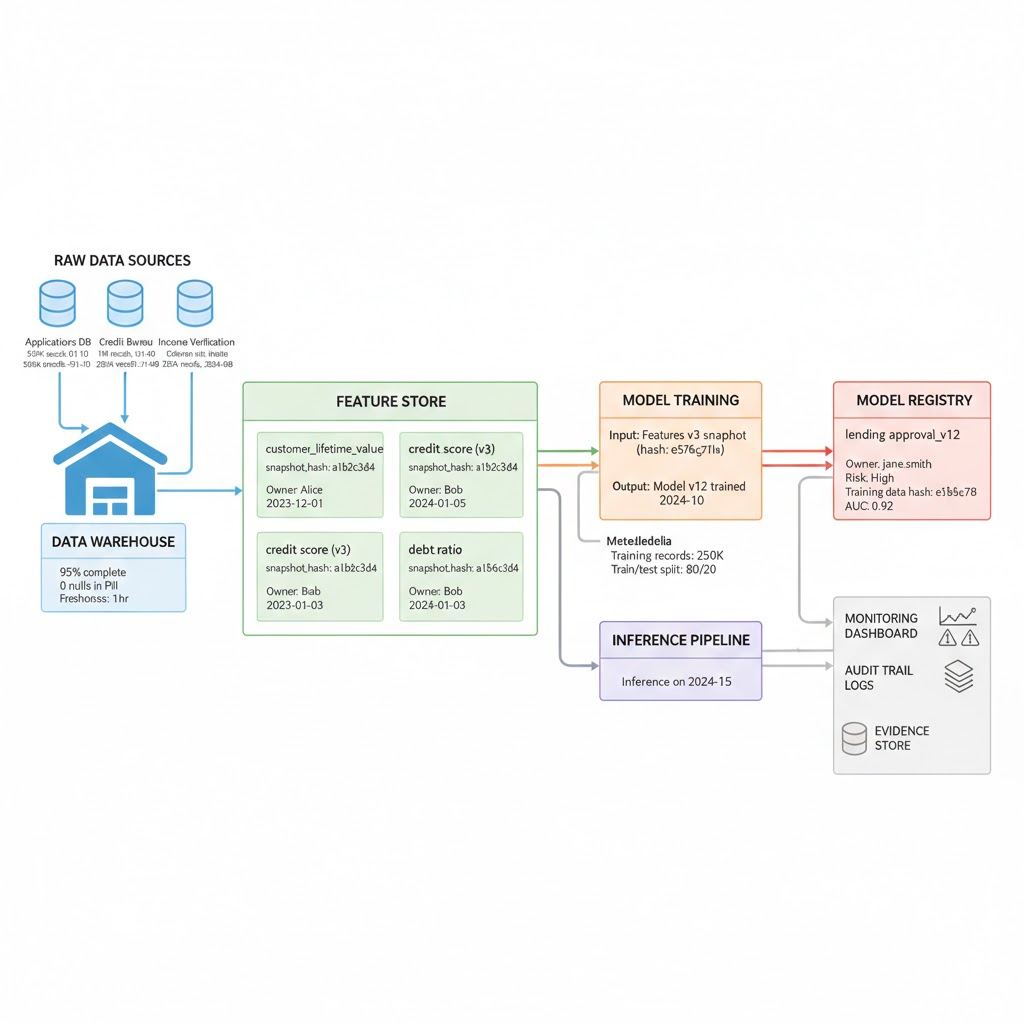
Implementation: Feature Store as Lineage Choke Point
If features are computed ad hoc in notebooks, lineage collapses immediately. A feature store (Tecton, Feast, Databricks Feature Store) enforces:
- Centralized feature definitions with versions
- Automatic lineage tracking (which source tables feed this feature?)
- Consistent reuse across models (no copy paste feature logic)
- Point in time correctness (inference uses the exact feature values from training time)
What this looks like operationally:
- Data engineer creates feature
customer_lifetime_valuein feature store, versioning it automatically - Feature definition includes: source table, transformation SQL, owner, retention policy
- When data scientist trains a model, feature store logs: feature version, training date, data snapshot hash
- When model deploys to production, inference pipeline retrieves features from same store, ensuring consistency
- If source table has data quality issue, data steward can trace which models are affected and when they were last trained
Cost reality: 4-8 weeks upfront to migrate features into a store, then 2-3 FTE to maintain. Feature fragmentation alone (features defined in 15 different notebooks) costs more than feature store maintenance.
For streaming/real time systems, event level lineage is expensive; use bounded aggregation with strong metadata (hourly snapshots with versioning).
For GenAI, prompt templates and retrieved documents must be first class lineage nodes (see GenAI section below).
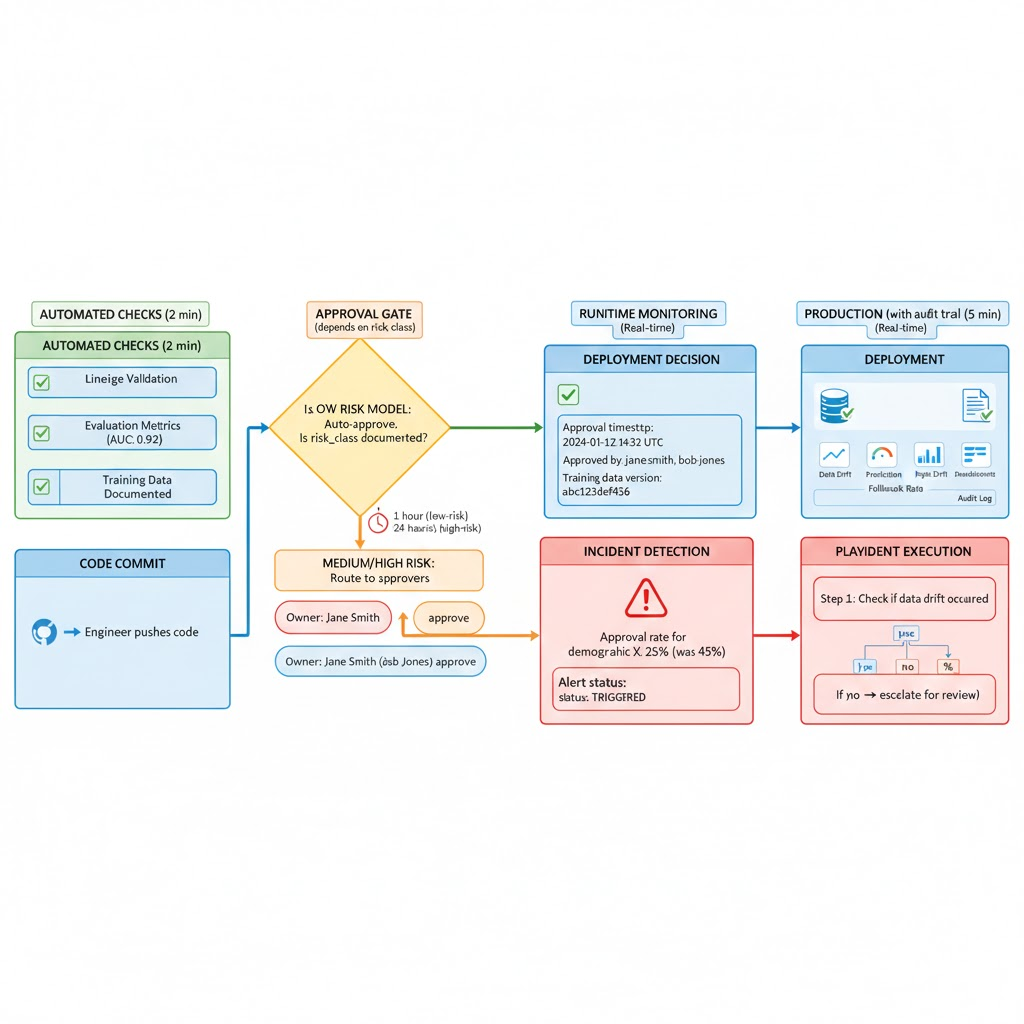
Step 4: Embed Governance Into the ML Lifecycle (Not as a Review Board)
Manual review boards do not scale and create bottlenecks. Governance must be enforced where work already happens: in your CI/CD pipeline and model registry.
Design Pattern: Policy as Code
Risk classification and approval rules are stored in code/configuration, not in spreadsheets or email threads.
In practice:
- Model registry (MLflow, Weights & Biases, SageMaker Model Registry) includes:
- Risk classification (low/medium/high)
- Owner name
- Required artifacts (lineage confirmation, evaluation metrics, bias assessment)
- CI checks block deployment if:
- Training data lineage is not documented
- Evaluation metrics don’t meet thresholds for risk class
- Risk classification missing or unreviewed
- Monitoring plan not configured
- Approval workflow:
- Low risk: Model owner self approves via model registry UI
- Medium risk: Peer review required (second senior IC approves)
- High risk: Model owner + risk/compliance reviewer both approve
- Deployment logging:
- Approval timestamp and approver identity
- Training data version hash
- Evaluation metrics at approval time
- Deployment timestamp and deployer
What This Looks Like in Code
model_metadata = {
"name": "lending_approval_model",
"owner": "jane.smith@company.com",
"risk_class": "high", # triggers formal review gate
"training_data_lineage": {
"source_datasets": ["applications_db.v2", "credit_bureau.v1"],
"snapshot_hash": "a1b2c3d4...",
"created_date": "2024-01-15"
},
"evaluation": {
"auc": 0.92,
"min_auc_for_deployment": 0.85, # tied to risk class
"fairness_parity_gap": 0.03,
"max_acceptable_gap": 0.05
},
"approvals": [
{"role": "owner", "approved_by": "jane.smith", "date": "2024-01-20"},
{"role": "compliance_reviewer", "approved_by": "bob.jones", "date": "2024-01-21"}
],
"deployed": "2024-01-22T14:32:00Z"
}
CI gate pseudocode:
if model_metadata["risk_class"] == "high":
if "compliance_reviewer" not in model_metadata["approvals"]:
fail_deployment("High risk models require compliance review")
if model_metadata["evaluation"]["auc"] < model_metadata["evaluation"]["min_auc_for_deployment"]:
fail_deployment("Evaluation does not meet threshold")
if not model_metadata["training_data_lineage"]["snapshot_hash"]:
fail_deployment("Training data lineage required")
Leave subjective judgment (ethical review for edge cases) to humans but only for high risk models. Everything else is automated.
Step 5: Monitor Behavior, Not Just Accuracy
Traditional ML monitoring focuses on performance metrics (accuracy, latency). Governance requires behavioural monitoring tracking whether the model is being used as intended and whether it’s drifting.
What to Monitor
Baseline signals:
- Data drift: Are inference inputs matching training distribution?
- Prediction drift: Are outputs shifting over time?
- Feature attribution changes: Which features matter most now vs. at training?
Governance specific signals:
- Out of context use: Is the model being used for purposes it wasn’t trained for?
- Unapproved data sources: Is inference data coming from sources not approved in training?
- Human override frequency: How often do humans override or reject model decisions?
- Fallback rate: How often does the system fall back to heuristics or manual review?
For high risk models, add:
- Demographic parity metrics: Does approval rate differ by demographic group?
- Disparate impact ratio: Is any subgroup rejected at 4x the rate of others?
- False positive/negative rates by subgroup
Making Monitoring Actionable: Alert → Playbook → Resolution
Every alert must map to a pre approved playbook. Without playbooks, teams ignore alerts.
Example 1: Feature Drift Alert
Alert: "Feature customer_credit_score from training source not present in 15% of inference requests"
Playbook:
1. Check if source is still operational (query source_db.credit_bureau)
2. If source is down: Page on call data engineer, begin failover plan
3. If source is up: Route alert to data steward (owner: sarah.lee@company.com)
4. Data steward investigates why feature computation failed
5. If feature is still valid: Fix feature store job, redeploy
6. If source deprecated: Update model owner that retraining required using new source
7. Log incident with resolution time in audit trail
Example 2: Demographic Drift Alert
Alert: "Approval rate for demographic group X dropped from 45% to 25% in last 30 days"
Playbook:
1. Check if input distribution changed (did applicants from group X change risk profiles?)
2. If yes: Document and monitor (expected drift, no action needed)
3. If no: Flag as potential model drift requiring human review
4. Model owner + compliance reviewer review sample decisions
5. If model behavior changed unexpectedly: Prepare retrain plan
6. If behavior is correct but appears unfair: Escalate to product team for business decision
7. Log decision and rationale in audit trail
Without these playbooks pre written, monitoring alerts become noise and get ignored.
Step 6: Design for Audits You Haven’t Seen Yet
Audits are inevitable. The goal is to make them cheap and fast.
Evidence You Will Be Asked For
- Complete model inventory with risk classification and owner
- Training data provenance: source systems, consent basis, retention policy
- Evaluation results at time of deployment
- Change history: when was model retrained? why? what changed?
- Incident logs: what went wrong? how was it resolved?
- Human oversight: who reviewed what? when? what was their decision?
Making Audit Response Automatic
If producing this evidence requires manual reconstruction, governance has failed.
Example Audit Scenario:
Regulator asks: “Your lending model denied John Doe’s application on January 15. Show me:
- What data was used to make that decision?
- What training data trained the model?
- How was the model approved for deployment?
- How often does the model deny applicants from his demographic group?”
Without governance:
- Search for application in database
- Find which model version was used
- Track down data scientist to ask what training data was used
- Ask compliance team for approval records
- Extract inference logs and manually calculate demographic parity
- Timeline: 2-3 weeks, multiple teams, manual processes
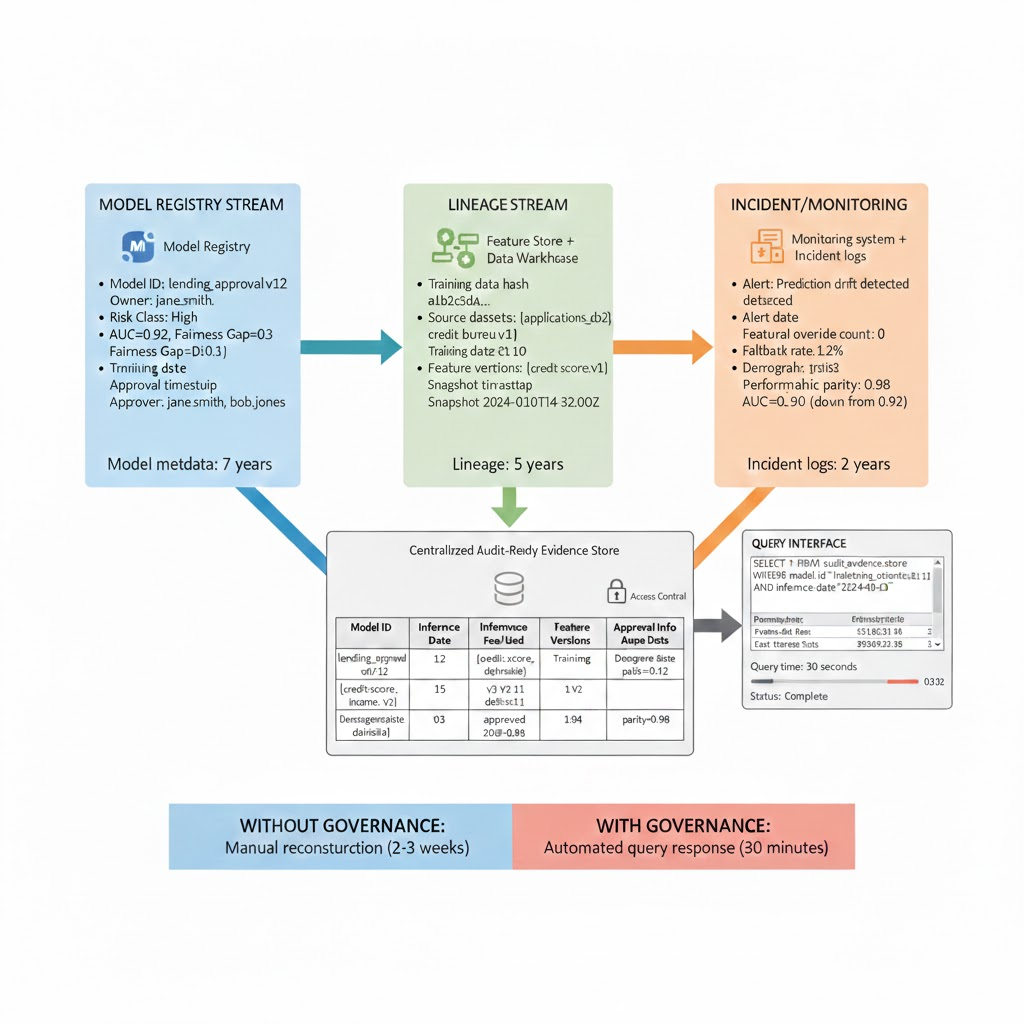
With governance (automated evidence pipeline):
Query: SELECT * FROM audit_evidence_store
WHERE model_id='lending_approval_v12'
AND inference_date='2024-01-15'
AND applicant_id='john_doe'
Returns:
{
"inference": {
"date": "2024-01-15",
"features_used": ["credit_score", "income", "debt_ratio", "age", "zip_code"],
"feature_versions": ["credit_score:v3", "income:v2", ...],
"prediction": "deny",
"confidence": 0.87
},
"training": {
"model_version": "lending_approval_v12",
"training_date": "2024-01-10",
"training_data_hash": "abc123def456",
"training_records": 250000,
"source_systems": ["applications_db", "credit_bureau", "income_verification"]
},
"approval": {
"owner_approval_date": "2024-01-12",
"compliance_reviewer": "bob.jones",
"compliance_approval_date": "2024-01-12",
"deployment_date": "2024-01-13"
},
"demographics": {
"approval_rate_overall": 0.62,
"approval_rate_same_age_group": 0.61,
"approval_rate_same_zip": 0.63,
"disparate_impact_ratio": 0.98 # No significant disparity
}
}
Timeline: 30 minutes. All evidence automatic, queryable, tamper proof.
Real World Implementation Story: Credit Model Governance
Here’s how a fintech company moved from “governance theater” to operational governance:
Starting state (Month 0):
- Credit approval model in production for 18 months
- Training data: multiple sources, unclear provenance
- Deployment: one engineer committed to main branch, no approval
- Monitoring: accuracy only, no behavioral signals
- Incident: Model denied 60% of applicants from ZIP 12345. Investigation took 3 weeks. Root cause: training data was accidentally sampled from high income areas only.
Implementation (Months 1-6):
Month 1: Ownership (Step 1)
- Define RACI: Credit team lead = model owner, Data steward = Sarah (data engineering), MLOps = platform team
- First governance failure: nobody knew who owned data quality. Assigned ownership explicitly.
Month 2-3: Risk Classification & Lineage (Steps 2-3)
- Classify credit model as high-risk (automated decisions affecting access to credit)
- Migrate features to feature store (Tecton): 4 weeks of engineering
- Document training data lineage: source tables, consent basis (applicants consented to credit checks), retention (7 years per regulation)
- First real problem: 3 source systems use different customer ID formats. Built mapping layer.
Month 4: Embed in CI/CD (Step 4)
- Add model registry (MLflow) with approval gates
- CI check: block deployment unless evaluation metrics meet threshold (AUC > 0.85 for high risk)
- First conflict: model had AUC 0.83. Owner wanted to ship anyway. Rule prevented it. Forced retraining instead of releasing risky model.
Month 5: Monitoring & Playbooks (Step 5)
- Deploy monitoring for data drift, prediction drift, demographic parity
- Write playbooks for: “What if approval rate drops by 10%?” “What if feature is unavailable?”
- First incident: Prediction drift detected (model was rejecting more applicants than at training time). Playbook triggered auto investigation. Found that income data source became more conservative. Triggered retrain workflow instead of emergency response.
Month 6: Audit Readiness (Step 6)
- Build audit ready evidence pipeline (model lineage → inference logs → decisions query able by applicant ID)
- First audit request: Regulator asks “Show approvals from Jan-Mar.” System returns: 47,293 decisions with feature values, training data versions, approval records, demographic breakdown. Done in 15 minutes.
Result (Month 6+):
- Deployment cycle: 1 week from training to production (was 2 months due to manual reviews)
- Incident resolution: 2 hours average (was 2 weeks)
- Audit cycle: 1 day (was 4 weeks)
- Risk: Significantly reduced (no more opaque decisions)
Common Failure Modes (Why Teams Get Stuck)
Even with governance in place, teams run into predictable problems:
Failure Mode 1: CI Gates Get Circumvented
What happens: Engineers create “emergency” deployment process that skips governance gates. Within weeks, half of deployments go through emergency path.
Why: Gates too strict or slow. Slows down legitimate work more than governance provides value.
Fix: Make gates granular by risk class. Low risk models: 1 hour approval. High risk: 1 day. Auto approve if metrics pass threshold.
Failure Mode 2: Monitoring Alerts Are Ignored
What happens: Monitoring system fires 100 alerts per week. Teams mute most of them. Real incidents get missed.
Why: Playbooks missing or unclear. Too many false positives.
Fix: Start with 3-5 critical signals, not 50. Write playbooks before deploying monitors. Measure playbook execution time.
Failure Mode 3: Risk Classification Becomes Political
What happens: Every model is marked “high risk” because stakeholders want more oversight, or marked “low risk” because teams want faster deployment.
Why: Classification tied to organizational politics, not actual impact.
Fix: Define risk in terms of: (1) automation level (autonomous decision vs. human in loop), (2) affected population size, (3) reversibility of decisions. Make it objective.
Failure Mode 4: Feature Store Becomes a Bottleneck
What happens: Feature store team gets overloaded. New features have 2-week backlog. Teams go back to computing features in notebooks.
Why: Underestimated feature store operational load.
Fix: Self service feature creation with templates. Governance on what can be self served (low risk) vs. requires review (high risk).
Failure Mode 5: GenAI Models Bypass Governance
What happens: GenAI teams say “governance is for traditional ML, not LLMs.” Deploy production RAG systems with no lineage, no approval, no monitoring.
Why: GenAI governance is different enough that teams think old rules don’t apply.
Fix: Explicit GenAI governance section (see below). Different controls, but governance still applies.
GenAI Governance: Special Considerations
GenAI systems (LLMs, RAG, agents) introduce new governance challenges:
What’s Different
- Non deterministic outputs: Same input can produce different outputs. Traditional evaluation metrics (AUC, precision) don’t apply.
- Complex lineage: Prompt + retrieved documents + fine tuned weights + temperature setting all affect output. Lineage is messy.
- Hallucination risk: Model can confidently state false information.
- Prompt injection: Adversarial inputs can bypass intended behavior.
GenAI Specific Controls
Prompt governance:
- Prompt templates treated as versioned artifacts in your version control
- Prompts reviewed before deployment for: jailbreak vulnerabilities, instruction injection risks, bias
- A/B testing framework for prompt versions
Retrieval governance (RAG systems):
- Source documents tracked with provenance and freshness
- Retrieval quality monitored (is RAG finding relevant documents?)
- Citation accuracy monitored (does model cite retrieved documents correctly?)
Output monitoring:
- Toxicity/policy violation rate (does model output violate content policy?)
- Hallucination proxy: citation mismatch (model cites documents it didn’t actually retrieve)
- User rejection rate (how often do humans reject model outputs?)
- Latency degradation (is context window becoming bottleneck?)
Example: Financial advisor LLM
- Low risk: Internal use, financial education (no financial advice given)
- Medium risk: Advisor recommendations, human reviews final advice
- High risk: Autonomous financial decisions (if this exists, reconsider it)
Controls: Prompt approval for medium/high risk, output monitoring for hallucination and toxic language, retrieval source approval (only approved financial documents in context).
Cost Reality: What You’re Actually Investing
Governance is not free. Here’s what it costs for a mid sized organization (20-50 deployed models):
Initial Implementation (Months 1-6)
Engineering effort:
- Feature store migration: 2-3 FTE × 4-8 weeks = $40-80K
- Model registry + CI/CD integration: 1 FTE × 4 weeks = $20-30K
- Monitoring + playbooks: 1 FTE × 4 weeks = $20-30K
- Audit evidence pipeline: 0.5 FTE × 4 weeks = $10-15K
- Total: $90-155K in engineering
Tooling:
- Feature store (Tecton, Feast): $0-50K/year (open source free, managed $20-50K)
- Model registry: $0-20K/year (MLflow free, managed options $5-20K)
- Monitoring: $10-30K/year
- Total: $10-100K depending on choices
Total upfront: $100-255K
Ongoing (Per Year)
Engineering:
- Feature store maintenance: 1 FTE = $120-150K
- Governance operations (incident response, playbook updates): 0.5 FTE = $60-75K
- Total: $180-225K/year
Tooling: $10-100K/year
Total: $190-325K/year
What You Avoid
- Regulatory fines (GDPR: 1-4% of revenue; EU AI Act: 6% of revenue)
- Incident remediation (average $500K-2M+ for large models)
- Audit costs (without governance: $50K-200K per audit cycle; with governance: $5K-10K)
- Model rollbacks due to undetected issues (cost of emergency retrain + data cleanup + user communication)
For most organizations, avoiding one regulatory incident pays for governance 10-50× over.
Realistic Timeline: Phased Rollout
Implementing all 6 steps in 4-6 weeks is fantasy. Here’s realistic:
Phase 1: Foundation (Weeks 1-8)
Focus: Steps 1-2 (Ownership + Risk Classification)
- Weeks 1-2: Define RACI for all models
- Weeks 3-4: Classify models by risk
- Weeks 5-8: Build model registry with ownership + risk fields
Success metric: Every model has a named owner and risk classification
Effort: 1-2 FTE
Phase 2: Data Control (Weeks 9-20)
Focus: Step 3 (Lineage)
- Weeks 9-12: Migrate high-risk models’ features to feature store
- Weeks 13-16: Document training data lineage
- Weeks 17-20: Integrate feature store with model registry
Success metric: High-risk models have complete lineage queryable by model ID
Effort: 2-3 FTE
Phase 3: Process Automation (Weeks 21-32)
Focus: Step 4 (CI/CD Gates)
- Weeks 21-24: Build CI checks (lineage validation, evaluation metrics)
- Weeks 25-28: Implement approval gates in deployment
- Weeks 29-32: Run pilot deployments through gated process
Success metric: All deployments require approval; low risk models auto approve if metrics pass
Effort: 1 FTE
Phase 4: Operations (Weeks 33-48)
Focus: Steps 5-6 (Monitoring + Audit Readiness)
- Weeks 33-36: Deploy monitoring for behavioral signals
- Weeks 37-40: Write + test playbooks
- Weeks 41-44: Build audit evidence pipeline
- Weeks 45-48: Run mock audits
Success metric: Audit queries return evidence in <1 hour; incidents detected and resolved via playbooks
Effort: 1.5 FTE
Phase 5: GenAI + Continuous Improvement (Weeks 49+)
Focus: GenAI governance + optimization
Effort: 0.5-1 FTE ongoing
Total timeline: 12 months (not 4-6 weeks)
Starting Blueprint: Minimal Viable Implementation
If you have limited resources, do this first:
Week 1-2: Name owners for 10 highest risk models
Week 3-4: Document where training data comes from (even if manual spreadsheet initially)
Week 5-6: Add risk classification to your model registry (MLflow, W&B, or custom)
Week 7-8: Block deployments that don’t include: owner name + risk class + evaluation metrics
This is not complete governance. But it’s a foundation. Everything else builds on it.
You can add feature stores, fancy monitoring, and audit pipelines later. These 4 weeks prevent the most common failures (unclear ownership, undocumented data, uncontrolled deployments).
Internal Link Suggestions
Tier 1 (Essential):
- Data Lineage for AI Compliance – Technical implementation of Step 3
- Data Governance Framework 2026 – Strategic context for all 6 steps
Tier 2 (Enrichment):
- Feature Store Design and Governance
- MLOps Monitoring Best Practices
- AI Compliance Incident Response