Netflix's algorithm doesn't just predict what you'll watch. It predicts what you'll watch after your second episode, what you'll watch at 11 PM on a Tuesday, and how long you'll actually stay subscribed. According to Netflix's engineering research, recommendations account for over 80% of what users click on across its platform. That's not a guess. That's the core of Netflix's business model. Understanding how these systems actually work reveals something uncomfortable: recommendation algorithms are surveillance systems designed to feel helpful.
The stakes matter. Spotify's recommendation engine helps retain users who would otherwise drown in 100 million songs. YouTube's algorithm keeps viewers watching for 1 billion hours daily. Amazon's product recommendations influence 35% of the company's revenue. These aren't nice-to-have features. They're the profit margins. But they also shape what billions of people consume, which shapes culture, news intake, and radicalization pathways. Getting this right (or wrong) affects the real world.
Three major platforms use different recommendation approaches but share the same goal: maximize engagement.
Featured Snippet: Recommendation systems are algorithms that predict user preferences by analyzing viewing history, content features, and similar users' behavior. Netflix, YouTube, and Spotify use a mix of collaborative filtering, content-based filtering, and neural networks to personalize suggestions. They work because they reduce choice overload, but they also limit discovery, reinforce existing preferences, and create filter bubbles that are harder to escape than most people realize.
Table of Contents
- What's actually happening under the hood
- How each platform builds recommendations differently
- Real limitations and what goes wrong
- The comparison: Netflix vs YouTube vs Spotify
- Who these systems benefit, and who they hurt
- The privacy cost nobody discusses
- FAQ
What's Actually Happening Under the Hood
A recommendation algorithm isn't magic. It's math trying to answer one question: given what we know about User A and what we know about Content B, how likely is User A to engage with Content B?
Netflix starts by collecting everything: what you watched, how long you watched it, when you paused it, whether you finished it, what you rated it, how many times you've rated anything, what device you used, where you're located, when you watched it, and what you searched for before finding it. That's thousands of data points per user. Then it runs that data through multiple algorithms simultaneously.
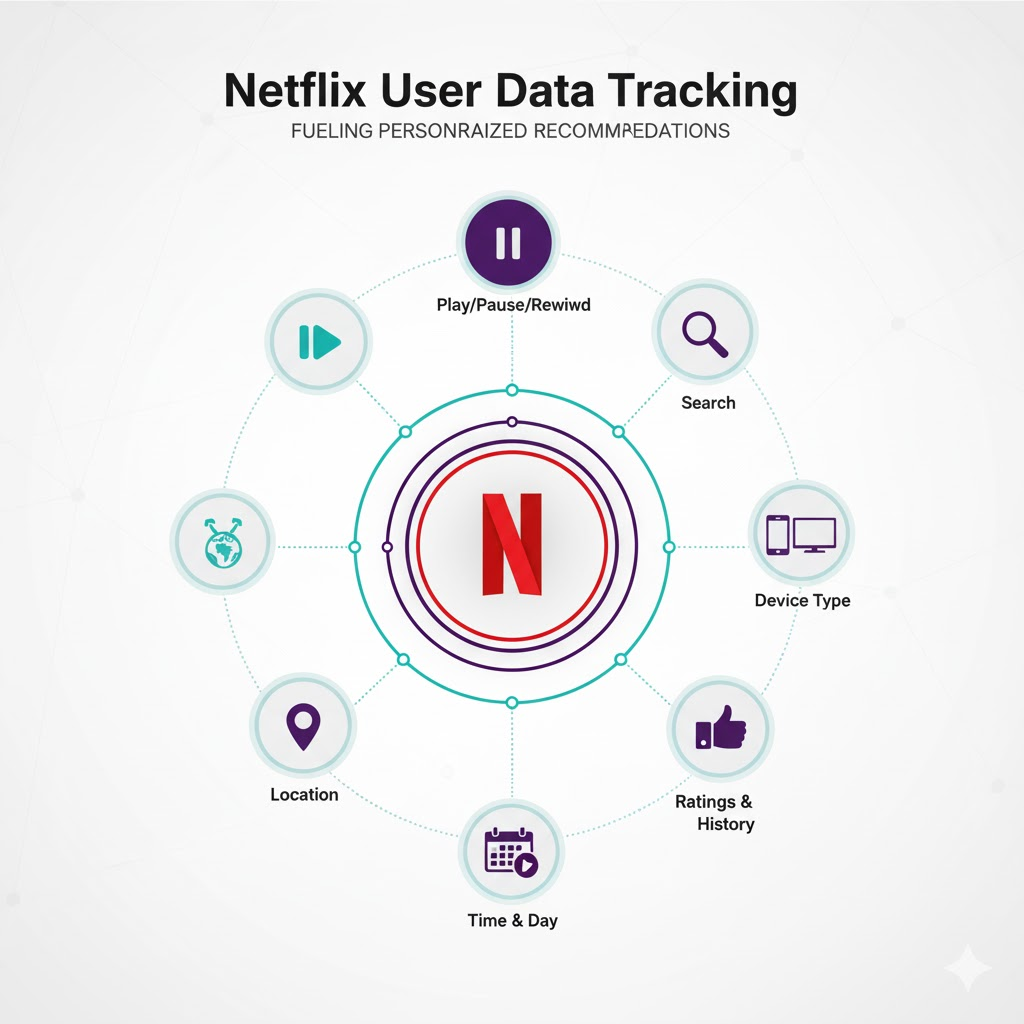
Netflix collects granular behavior data at every interaction point to train its recommendation models.
Some use collaborative filtering, which finds users with similar viewing histories and recommends what those similar users watched. If you and another person watched the exact same 15 shows, the algorithm might recommend to you what that person watched next, even if you've never heard of it. This approach works well when you have massive amounts of user behavior data, but it fails completely for new users or new content (the "cold-start problem"). Understanding how collaborative filtering works is essential to grasping why these systems succeed or fail, and our guide to machine learning fundamentals covers the mathematical foundations behind this approach.
Others use content-based filtering, analyzing what you already watched and finding content with similar characteristics. If you watched three documentaries about nature, the system finds other nature documentaries based on metadata like genre, narrator, runtime, or production studio. This works for new users but tends to create narrow recommendation feeds because it defaults to extreme similarity.
Advanced systems use neural networks trained on interaction patterns. These models learn non-obvious relationships. A Netflix network might learn that people who watch dark comedies at midnight on weekends have a 67% chance of watching horror after finishing a specific drama. These patterns aren't explicitly programmed. The model discovers them through training on billions of user interactions. To understand how these systems actually learn, our article on how neural networks mimic the human brain explains the architecture that powers modern recommendation engines.
Netflix also uses something called contextual bandits, which is structured experimentation embedded in the algorithm itself. The system tries different rankings simultaneously, learns which ones perform best, and automatically shifts toward winners. If showing drama first converts more new subscribers than showing sci-fi first, within days the algorithm adapts. This makes Netflix's recommendations a moving target. You're not just seeing personalized suggestions. You're participating in an ongoing A/B test.
The sophistication is often overstated in marketing materials. Netflix doesn't have a single "recommendation algorithm." It has dozens working in parallel, each ranking potential content differently. The system then ensembles these rankings (combines them with weighted averages), but it also constantly experiments with how much weight each model gets. A version of Netflix you see for one week might show you dramatically different homepages than your friend's, and both are experiments. Netflix's engineering team publishes that they run thousands of experiments monthly. Most fail. The ones that increase watch time or reduce cancellations by even 0.1% get rolled out globally.
YouTube's system is more ruthless because its incentives are more explicit. It ranks potential videos first by "predicted click-through rate" (will you click on this?), then by "predicted watch time" (will you keep watching?), and finally by "predicted satisfaction" based on your return visits. But satisfaction is the problem. YouTube doesn't actually know if you're satisfied. So it uses a proxy: do you come back? Do you watch again tomorrow? Do you click? These proxies aren't perfect. Someone could watch a 10-hour rabbit hole of conspiracy theories with high engagement but zero actual satisfaction. The algorithm can't distinguish between "addicted" and "satisfied." It doesn't try.
Spotify's approach is different because music consumption is fundamentally different. A song is three minutes. You can listen to 20 a day. Listening history is massive but noisier. Instead of predicting "will you watch" Spotify predicts "will you skip." Skips are the clearest signal of dislike. So Spotify's models are built around minimizing skip rates. It also uses raw audio features, analyzing the actual waveform to measure tempo, key, timbre, and acousticness. This lets Spotify find similar songs even if nobody else has listened to both. A song by an unsigned artist can be recommended based on its audio similarity to a popular track, bypassing the cold-start problem that dooms other systems.
All three systems have a cold-start problem. New users have no history. New content has no data. For new users, platforms often fall back on popularity (what's trending) or ask explicit questions (what do you like?). For new content, they rely on metadata or give it to users similar to whoever added it to the platform. This is why brand new shows sometimes get random recommendations: they're being tested against multiple user segments simultaneously to generate the data needed for collaborative filtering to work.
How Netflix's Recommendation Engine Works in Practice
Netflix's dominance in recommendations comes from scale and ruthlessness. The company can afford to collect more data than competitors, run more experiments, and optimize for a single metric: subscription retention.
The homepage you see isn't generated fresh every time. Netflix pre-computes recommendations and stores them. When you open Netflix, you're seeing pre-ranked content built for users similar to you, not a real-time calculation. This is efficient but also limits surprise. Netflix knows your behavior patterns well enough to build a profile that predicts weeks in advance what you might watch.
Netflix also uses a technique called "learning to rank." The system learns not just whether you'll click something but the relative ranking. Show a user five recommendations, and the algorithm learns from which one they click first, whether they scroll to see more options, and whether they come back later to watch what they skipped. All of this feeds back into the model. The next time that user opens Netflix, their homepage has shifted slightly based on what they didn't watch today.
The company has published research showing they use reinforcement learning, a technique where the algorithm optimizes for long-term retention rather than immediate clicks. This is important. An algorithm optimizing for clicks might recommend a 30-minute feel-good comedy that you watch immediately. An algorithm optimizing for long-term retention might recommend something slightly less obvious that keeps you subscribed longer. These two goals often conflict.
But Netflix's recommendations have a real weakness: they assume you know what you want to watch. Show you a horror thumbnail, and you're likely to click horror. Netflix rarely breaks its own pattern and pushes unfamiliar genres or formats. A Netflix user who's watched 200 hours of comedies might have never seen a single Italian drama because the algorithm never breaks its established pattern. Netflix optimizes for engagement, not discovery. The two often conflict. This is why many Netflix users report "scrolling forever without finding anything" despite 15,000 available titles. The recommendation system creates a personal feed so narrow that browsing feels futile. This problem extends to how Netflix personalizes recommendations for different regions and languages, meaning viewers in different countries see fundamentally different catalogs, even for the same content.
How YouTube's Algorithm Creates Engagement (and Radicalization Paths)
YouTube's recommendation system is the most studied because its impact is the most controversial. Unlike Netflix, YouTube has no paywall. Revenue comes from watch time and ads. This creates perverse incentives. The algorithm is optimized to maximize engagement, which means maximizing time on platform and clicks. Time and truth rarely align.
YouTube selects from hundreds of candidate videos for each slot on your homepage using what the company calls "candidate generation." It scores them on predicted watch time first. A conspiracy theory video might be predicted to hold attention longer than mainstream news because it's more emotionally activating. So YouTube shows it. Then engagement data flows back (did you watch it? did you skip it? did you watch the next recommended video?). The algorithm learns that conspiracy content performs well for certain users. Within weeks, the algorithm has built a radicalization funnel without any human or explicit decision to do so. Researchers studying YouTube's recommendation algorithm have documented this process repeatedly, showing how innocent interests can gradually shift toward extreme content.
YouTube's engineers acknowledged this in 2019 when the company confirmed it had deliberately changed its algorithm to reduce recommendations of borderline content after complaints about conspiracy theory amplification and misinformation spread. But even with this intervention, YouTube's recommendation system still drives more extreme content than alternatives because extremity correlates with engagement. The business model didn't change. The incentive structure didn't change. Only the edge cases were trimmed.
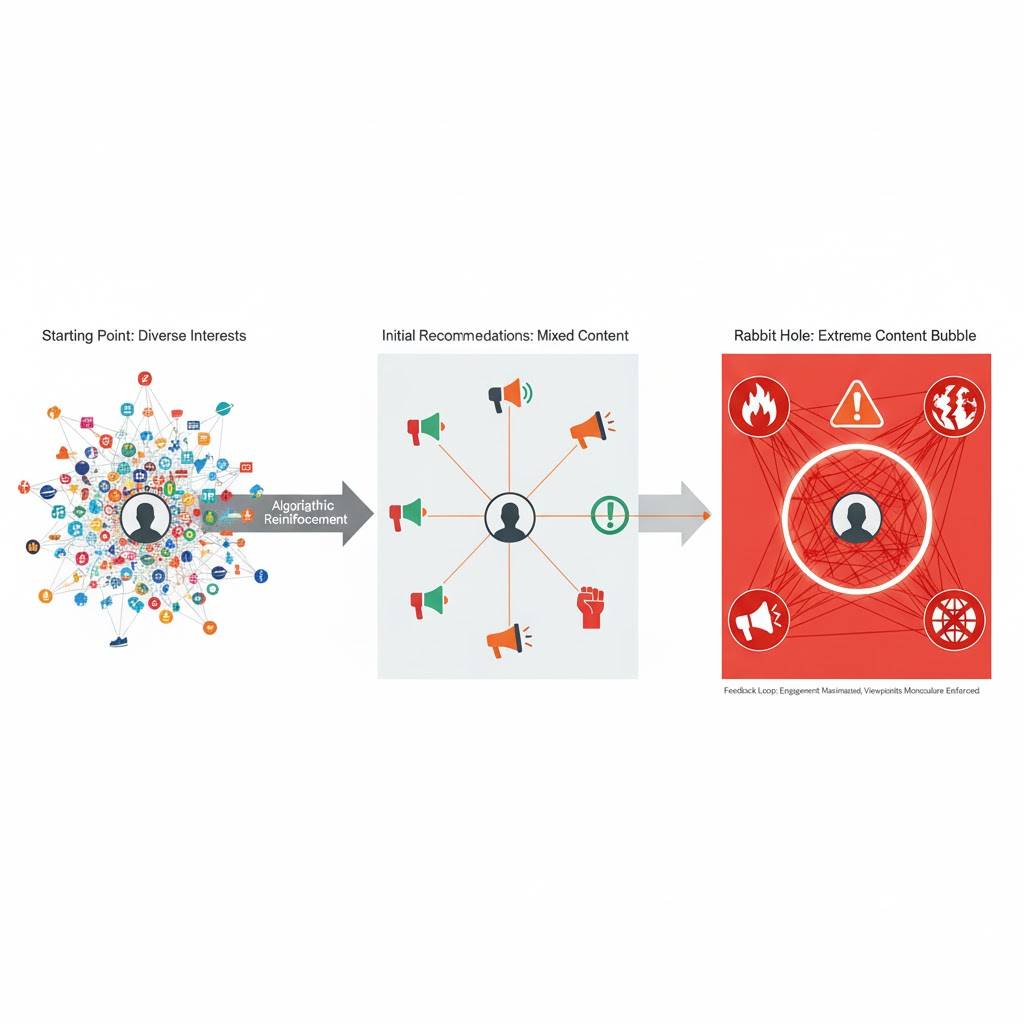
YouTube's algorithm gradually narrows your information diet by recommending increasingly similar content.
The deeper problem is that YouTube's algorithm can't distinguish between "engagement" and "harm." Someone watching a conspiracy theory for three hours generates the same engagement metrics as someone genuinely learning something useful. The algorithm treats them identically. It only knows that watch time increased. It can't know that one viewer is being radicalized and the other is being educated.
YouTube also shows personalized recommendations, meaning your neighbor watching the exact same video will see a completely different set of "next" suggestions. This creates filter bubbles where two people can watch YouTube in completely different information universes. YouTube doesn't show you this. The algorithm works invisibly. Understanding how YouTube's recommendation algorithm affects your information diet is one of the first steps toward digital literacy in the modern internet.
How Spotify's Music Recommendation System Balances Similarity and Discovery
Spotify's challenge is different from video platforms. Music listening is deeper and more frequent. Users listen to thousands of songs yearly, so Spotify has massive behavioral data. A user who's heard 10,000 songs has 10,000 data points for collaborative filtering to work with.
Spotify uses three main approaches simultaneously. First, collaborative filtering finds users similar to you based on what you've listened to and shows you their favorite songs you haven't heard. Second, content-based filtering finds songs similar to your favorites using audio features and metadata. Third, natural language processing analyzes what people write about songs on social media and playlists to understand cultural context.
Spotify's Discover Weekly playlist is the most visible output, but it's the least sophisticated algorithmically. It's built weekly for each user, combining your listening history with human-curated editorial playlists and recommendations from similar users. The playlist succeeds because it resets weekly. You get novelty and personalization in one package. But Discover Weekly is as much marketing as algorithm. Spotify publishes the playlists on social media, and users share them too, creating a feedback loop that makes them feel more valuable than they are.
Spotify's real strength is in radio stations and autoplay. When you turn on a song's radio station, Spotify chains together songs that flow together based on audio similarity and user skip patterns. The algorithm learns what transitions work and what don't. This is why autoplay often feels seamless even when songs are by completely different artists.
But Spotify also has a discovery problem. Heavy listeners develop tastes so specific that the algorithm struggles to find truly new music. After you've heard 100,000 songs, the marginal new song feels increasingly rare. Spotify pushes podcasts partly because podcast recommendation is still inefficient, so podcasts offer growth upside that music doesn't. The algorithm has saturated.
Netflix vs YouTube vs Spotify: Direct Comparison
All three platforms claim personalization, but they optimize for completely different outcomes. Netflix wants monthly retention. YouTube wants daily watch time. Spotify wants to keep you subscribed while also reducing server costs through efficient recommendations.
Netflix's recommendations are most accurate for deciding what to watch because Netflix optimizes for a clear binary: finish or don't finish. Netflix knows exactly when you stopped. YouTube's predictions are less accurate because watch time is noisy (you might keep a video playing while doing something else) and diverse (one person watches 5-minute clips, another watches 3-hour documentaries). Spotify's recommendations are most serendipitous because music is short enough to let you discover things quickly without massive time commitment.
On discovery, Spotify wins. The platform balances personalization with novelty through playlists, radio stations, and collaborative features. Netflix discourages exploration through its interface (you have to search hard for unfamiliar genres). YouTube's discovery is actively dangerous because it optimizes for engagement, not serendipity or truth.
On privacy, all three collect aggressively. Netflix knows your viewing habits at minute-level granularity. YouTube knows this too plus your search history plus your location. Spotify knows your music taste, time of listening, social features, and device. All three sell this data indirectly through targeted ads (Netflix is newer to ads but moving there). Netflix at least doesn't track you across websites. YouTube and Spotify do through pixels and integrations.

Netflix, YouTube, and Spotify optimize for different metrics, leading to fundamentally different recommendation behaviours.
| Factor | Netflix | YouTube | Spotify |
|---|---|---|---|
| Optimization metric | Subscription retention | Watch time / engagement | Skip rate minimization |
| Recommendation accuracy | High (clear engagement signal) | Medium (noisy signals) | High (explicit skip data) |
| Discovery potential | Low (algorithmic conservatism) | High but skewed (toward extreme) | High (balanced curation) |
| Privacy invasiveness | High | Very high | High |
| Algorithmic bias risk | Medium (repeats preferences) | Very high (filter bubbles) | Medium (genre gatekeeping) |
| Cold-start problem severity | High (needs history) | Medium (uses popularity) | Medium (audio features help) |
Real Limitations Nobody Wants to Discuss
Recommendation algorithms have systematic problems that scale intensifies rather than solves.
The first is the filter bubble problem. An algorithm that gets better at predicting your preferences also gets better at showing you only your preferences. Feed you enough Netflix comedies and the algorithm stops showing you dramas. Feed YouTube user enough left-wing commentary and it struggles to show mainstream news. The algorithm isn't trying to radicalize you. It's just optimizing for engagement, but engagement amplifies whatever you already like. You end up in a narrower media diet than you chose consciously, but you don't realize it because the narrowing happens gradually. By the time you notice, the algorithm has spent months training you to prefer only content that matches your existing beliefs.
The second is the cold-start problem for niche content. Netflix recommends billions of hours of mainstream content yearly but barely recommends niche documentaries or international films unless you actively search. Why? Because they have fewer users. Collaborative filtering can't work when only 10,000 people watched something. So recommendations become a winner-takes-all system where popular content gets promoted and niche content disappears. This kills discovery of great work that doesn't have massive appeal upfront. A brilliant Polish thriller watched by 50,000 people globally will never get recommended to Netflix users who haven't explicitly sought it out. Mainstream comedies get billions of impressions while niche content gets buried.
The third is algorithmic bias. If a training dataset reflects human bias (for example, if female creators' content is tagged with different genres or if content in certain languages gets downranked), the algorithm learns and amplifies that bias. YouTube has been caught amplifying misogynistic content more readily than sexist content because its training data (user behavior) was skewed. Netflix's algorithm was shown to recommend different genres to different users based on demographic data, even when controlling for viewing history. These aren't bugs. They're artifacts of the data the platforms trained on. The algorithm learned to discriminate because it learned from a discriminatory dataset. For a deeper exploration of this problem, our comprehensive article on AI ethics challenges and future dangers examines how bias enters systems and propagates at scale.
Recommendation algorithms amplify biases present in training data, creating discriminatory feedback loops.
The fourth is the proxy problem. YouTube optimizes for "predicted watch time," but watch time isn't what YouTube actually wants. YouTube wants engagement and ad revenue. These correlate but don't perfectly align. Someone could watch a 2-hour video and skip every ad. Someone could watch 10 minutes of ads consecutively. The proxy is wrong, and the algorithm adapts to it. This is why YouTube shows addictive content rather than good content. It's optimizing for the wrong metric and can't tell the difference.
The fifth is the business model problem. Recommendation systems in free or ad-supported platforms are built to maximize engagement, which means maximizing time on platform and clicks. Time and truth rarely align. Facebook and YouTube both learned that inflammatory content generates 10x more engagement than balanced content. Both tried to reduce it, but their underlying incentive structure pushes back. Building a recommendation system that prioritizes truth over engagement would require fundamentally different business model. Neither platform has done this.
Who These Systems Actually Benefit
Recommendation systems are Pareto-optimal: everyone benefits but not equally. Platforms benefit the most (they get retention and revenue). Power users benefit (they find content faster). But casual users and niche creators lose. The casual user sees only mainstream content. The niche creator can never build an audience because their work never gets recommended.
Netflix users who watch primarily mainstream content get better recommendations than users with eclectic taste. YouTube users interested in trending topics get more useful recommendations than users interested in niche communities. Spotify users with mainstream taste get better music discovery than users exploring obscure genres.
This matters because recommendation algorithms don't just optimize for accuracy. They optimize for business metrics. Netflix optimizes for retention because retention equals subscription revenue. YouTube optimizes for watch time because watch time equals ad inventory. Spotify optimizes for engagement and also for cost efficiency (recommending music that's licensed cheaply). The algorithms are honest about their goals only internally. To users, they present as objective truth. They're not. They're business instruments.
The Privacy Dimension: What Gets Collected
Building accurate recommendations requires invasive data collection. Netflix knows when you paused Mad Max at 1:47 PM on a Thursday. YouTube knows you searched for "anxiety treatment" and what videos you watched next. Spotify knows you listened to sad songs exclusively between 2 AM and 4 AM for two weeks. This data is gold for marketers and terrifying for privacy advocates.
All three platforms use this data internally to improve recommendations. All three also sell it to advertisers, though indirectly. Netflix doesn't sell data to third parties (yet, though this may change with their ad tier), but YouTube and Spotify do through tracking pixels and data partnerships. You're not the customer. Advertisers are.
The privacy cost extends to your social graph too. Spotify shares what you listen to on Facebook by default. Netflix reveals your ratings in some contexts. YouTube shows your watch history to Google. There's no true anonymity in recommendation systems because the data is so detailed that even "anonymized" data can identify individuals. Researchers have shown they can re-identify supposedly anonymous viewing data by comparing it to other datasets. Your taste profile is essentially a fingerprint.
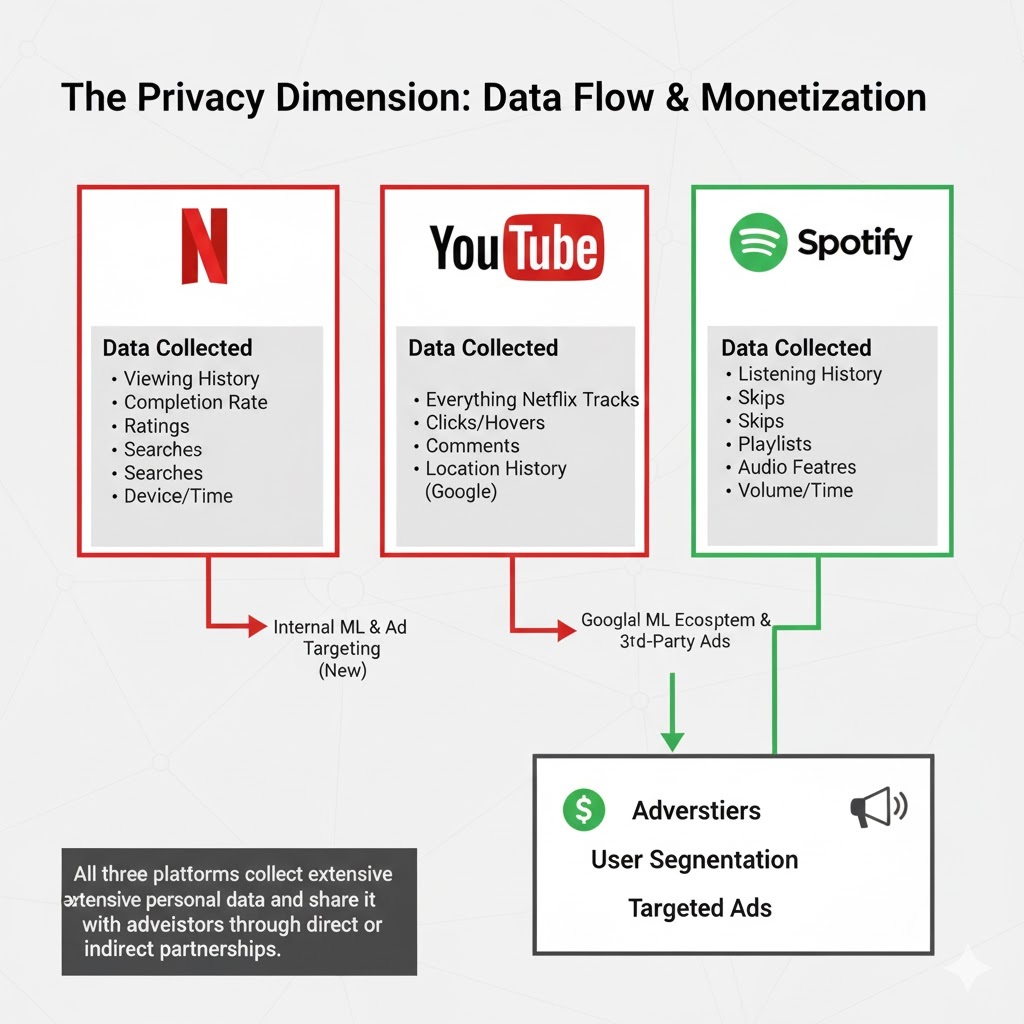
All three platforms collect extensive personal data and share it with advertisers through direct or indirect partnerships.
The recommended content also becomes data. What YouTube recommends to you teaches YouTube more about you. What Netflix suggests trains Netflix on your implicit preferences. The act of being recommended something reveals information about you to the platform. This creates a feedback loop where surveillance becomes increasingly invasive with each interaction.
The Future: Explainability and Cross-Platform Convergence
Recommendation systems are moving in two directions simultaneously. First, toward explainability (the ability to tell users why something was recommended). This helps trust but also helps users game the algorithm. Show Spotify you listened to a classical piece once and delete it from history, and the algorithm might stop recommending based on it. Explainability is good for users but complicates the business of recommendation.
Second, toward cross-platform personalization where your Netflix watching influences Spotify recommendations and vice versa. Amazon already does this. Your shopping history influences your video recommendations. This is efficient recommendation but totalizing surveillance. Your entire online behavior becomes data that feeds into predictions. The upside is personalization. The downside is that you're never truly anonymous.
There's also movement toward contextual recommendations. Systems that know it's Monday morning might recommend productivity content or upbeat music. Systems that know you're at the gym might recommend high-energy songs. This is theoretically useful but also deeply invasive. It requires tracking your location, time, and context constantly.
The real frontier is multimodal AI that understands not just what you watched but what you said about it, what your friends watched, what's trending in your region, what similar users loved, what the content's actual quality is, and dozens of other signals. These systems will be more accurate and also less transparent. A recommendation powered by 500 different signals is impossible to explain. You'll have to trust the algorithm because you can't audit it.
Conclusion
Recommendation systems aren't just algorithms. They're business decisions disguised as math. Netflix, YouTube, and Spotify have all built systems that work because they're ruthlessly optimized for their specific goals. Netflix's work because they know exactly what retention looks like. YouTube's work because watch time is measurable and engagement drives revenue. Spotify's work because short-form content allows rapid feedback and iteration.
But these systems are also narrowing what we see, amplifying what we already believe, and collecting invasive data to do it more effectively. The algorithm works. Whether it should work this way is a different question. Understanding how recommendations actually function is the first step toward demanding something better. Right now, we're stuck with systems built by engineers optimizing for metrics that don't always align with what users actually need.
The most important takeaway is this: you're not the user of these systems. You're the product being optimized. The real users are Netflix shareholders, YouTube advertisers, and Spotify's license holders. The recommendations you see are optimized for their benefit, not yours. Sometimes these align. Often they don't.
FAQ
Q: How does Netflix know what I want to watch if I've never rated anything?
A: Netflix uses thousands of data points beyond ratings: what you've watched, how long you watched it, what you searched for, what time you watched it, what device you used, whether you paused or rewound, and what similar users watched. If you and another user have watched the exact same 10 shows, Netflix will recommend what that user watched next, even without explicit ratings. This is collaborative filtering, and it works with pure behavioral data.
Q: Can I make recommendations worse by changing my behavior?
A: You can, but Netflix has protections against this. If you watch something you hate and immediately turn it off, Netflix learns from the abandonment, not the rating. Deliberately skipping content also trains the algorithm. But Netflix doesn't publicly disclose how it weighs these signals relative to each other, so you can't reliably poison the algorithm. The system is designed to be manipulation-resistant, though not perfectly.
Q: Why does YouTube keep recommending conspiracy theories even after YouTube changed its algorithm?
A: YouTube did deprioritize borderline content like conspiracy theories, but it didn't remove the incentive to create them. Conspiracy theories generate higher engagement than mainstream content. Users watch longer, click more, and return more frequently. So even with algorithmic changes, the underlying business model incentivizes recommendations that drive consumption over accuracy. YouTube can't solve this without changing how it makes money, which it won't.
Q: Is Spotify's Discover Weekly actually good or is it just marketing?
A: It's both. Discover Weekly is algorithmically competent (built from real collaborative filtering and content-based filtering), but it's highly curated for social sharing. Spotify knows users share their Discover Weekly playlists on social media, which drives engagement and word-of-mouth. The algorithm is good, but the presentation is designed for viral moments. It works, but not purely because of algorithmic sophistication.
Q: What's the difference between good recommendations and invasive surveillance?
A: Accuracy. A recommendation system that suggests 10 videos and you click 5 is working well. A system that suggests 10 videos and you click 0 is failing. But both require the same data collection. The difference is whether you consented and whether you can opt out. Most platforms don't let users opt out of recommendations without opting out of the service entirely. This is surveillance disguised as personalization.
Sources
- Netflix Technology Blog - Learning to Rank Recommendations - Netflix's research on reinforcement learning and long-term retention optimization in recommendations
- YouTube Official Blog - How YouTube Recommends Videos - YouTube's technical explanations of ranking systems, candidate generation, and recent algorithmic changes
- Spotify Engineering - Recommendation Systems at Scale - Spotify's technical documentation on collaborative filtering, content-based approaches, and audio feature analysis
- MIT Media Lab Research on Filter Bubbles - Academic research on algorithmic filter bubbles and polarization effects
- Stanford Internet Observatory - YouTube Recommendation Study - Research on YouTube's recommendation algorithm and content radicalization pathways
- Association for Computing Machinery - Algorithmic Bias in Recommendations - Peer-reviewed research on bias amplification in recommendation systems
- Electronic Frontier Foundation - Recommendation Algorithm Privacy - Analysis of privacy implications and data collection by recommendation systems