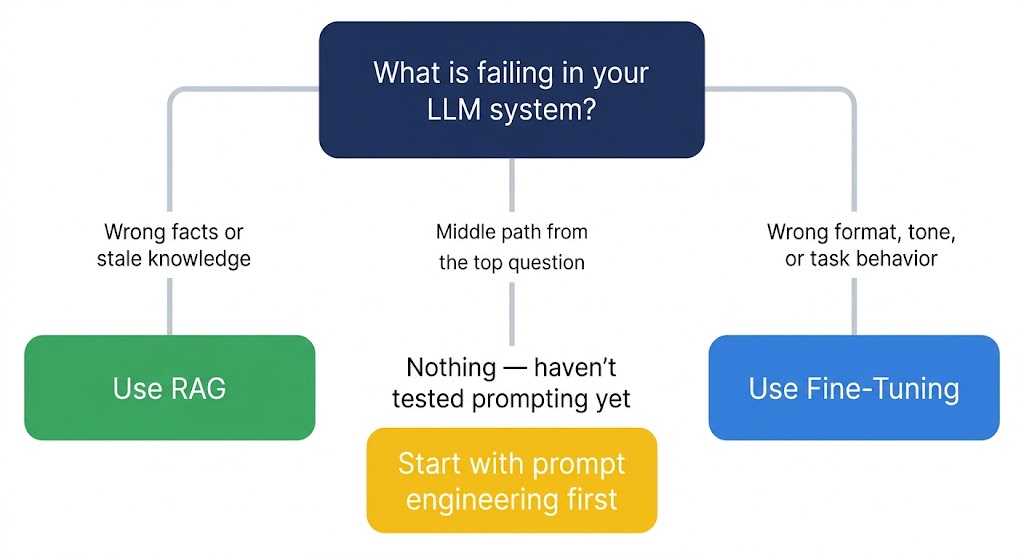
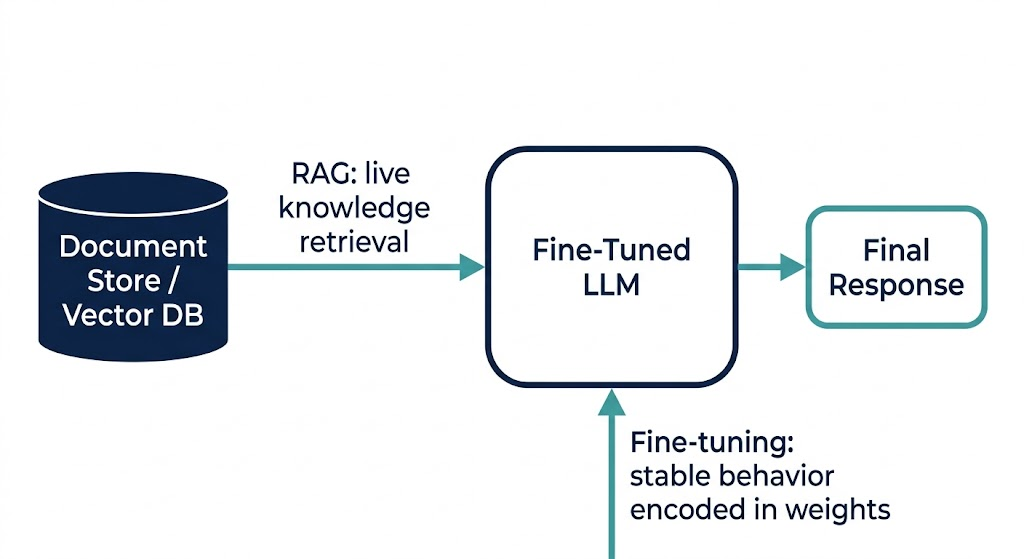
RAG improves an LLM by giving it access to external knowledge at query time, without changing the model. Fine-tuning improves an LLM by retraining it on your data to change how it behaves. Use RAG when your model gets facts wrong or uses stale information. Use fine-tuning when it responds inconsistently, ignores formatting rules, or underperforms on a specific task.
Introduction
A team spent three months building a fine-tuned model for internal support. They curated training data, ran multiple GPU jobs, iterated on hyperparameters. The model launched. Users complained it was still giving wrong answers about current product pricing.
The problem was never behavior. It was always knowledge. A RAG pipeline over their documentation would have shipped in two weeks and cost under $500.
This failure pattern is not rare. Teams default to fine-tuning because it feels more technically serious more "AI-native." The result is wasted budget, delayed launches, and a model that confidently produces outdated facts with perfect formatting.
The RAG vs fine-tuning decision is not a technology preference. It is a diagnostic question: what is actually broken in your system? Get the diagnosis right and the architecture choice follows naturally. Get it wrong and you spend months solving the wrong problem.
This guide covers how each approach works, where each fails, what both actually cost in 2026, and a framework for making the call before you build anything.
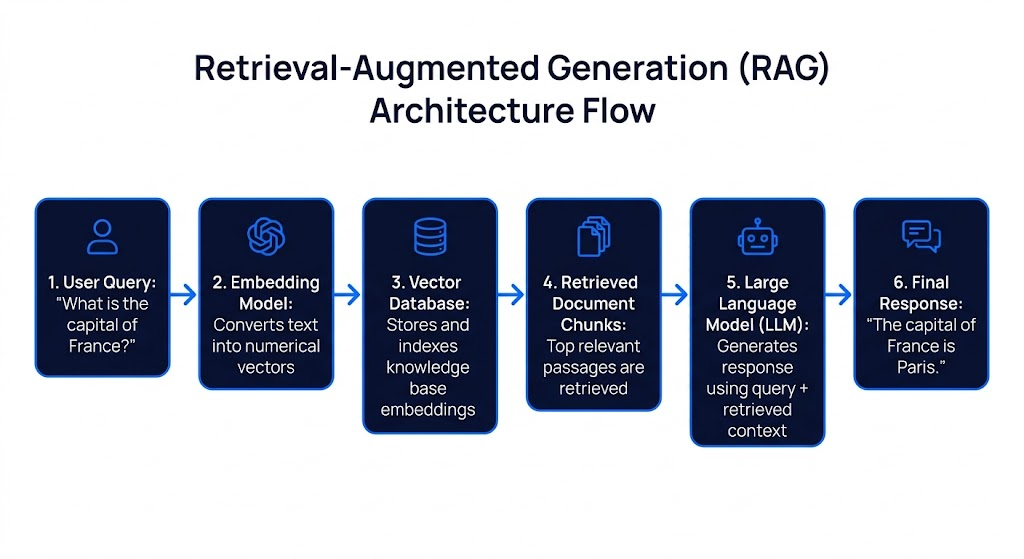
What RAG vs Fine-Tuning Actually Means
These two approaches solve fundamentally different problems, which is why comparing them directly misleads most teams.
Retrieval-Augmented Generation (RAG) connects a base LLM to an external knowledge source a vector database, document store, or search index. At query time, the system retrieves relevant document chunks and injects them into the model's context window. The model itself is never modified. The intelligence stays in the base model; RAG just gives it better information to reason over.
Fine-tuning modifies the model's weights by training it further on a task-specific dataset. The result is a model that behaves differently it follows your output format reliably, uses your domain terminology correctly, or performs better on a narrow classification task. But it only knows what was in the training data, and that knowledge is frozen the moment training ends.
The cleanest way to hold the distinction: RAG changes what the model knows at runtime. Fine-tuning changes how the model behaves permanently.
Why the Decision Matters More Than Ever
Three things have shifted this choice from a technical detail into a strategic one.
The cost of getting it wrong has increased. Fine-tuning is cheaper than it was in 2023, but total project costs including data preparation, iteration cycles, and ongoing retraining still run from $1,000 to $30,000+ depending on approach and model size. Teams that fine-tune to solve a knowledge problem pay those costs and still ship a broken system.
Data freshness requirements have tightened. Regulatory requirements, product catalogs, and internal policies change faster than retraining cycles. A fine-tuned model trained in January will confidently cite outdated compliance rules in March. RAG handles this without touching the model.
The quality bar for production has risen. According to a Gartner projection from 2024, 80% of enterprise RAG implementations were expected to fail by 2026, with poor data quality as the primary cited cause. That statistic matters because it reframes the decision: neither approach saves you from bad data, and both require deliberate data infrastructure to perform at production quality.
Core Components of Each Approach
RAG: The Three Moving Parts
Embedding model. Converts your documents into vector representations that capture semantic meaning. The quality of your embeddings directly determines retrieval quality. A weak embedding model or one not tuned for your domain's terminology is the single most common cause of poor RAG performance.
Vector store. Stores and indexes document embeddings. Options range from managed services like Pinecone to self-hosted solutions like pgvector on PostgreSQL. The right choice depends on your scale, latency requirements, and whether your infrastructure team wants another service to maintain.
Retrieval and ranking layer. Finds the most relevant document chunks at query time and ranks them before injection. This is where most RAG implementations underinvest. Retrieval precision getting the right chunks, not just semantically similar ones requires chunking strategy, metadata filtering, and often hybrid retrieval (combining vector search with keyword matching).
The overlooked dependency: data governance. RAG quality degrades sharply without clean, governed source data. Well-governed data produces retrieval accuracy in the 85–92% range; ungoverned data drops that to 45–60%. The decision to use RAG is simultaneously a decision to govern the data it retrieves from.
Fine-Tuning: The Methods That Actually Matter in 2026
Full fine-tuning. Updates all model parameters. Maximum customization, maximum compute cost. A 70B model requires roughly 140GB VRAM just to hold weights in FP16 before adding optimizer states. Rare in production for most teams.
LoRA / QLoRA (Parameter-Efficient Fine-Tuning). Freezes the base model and trains small adapter layers on top. QLoRA adds 4-bit quantization, enabling fine-tuning of 7B models on a single consumer GPU. This is the standard approach for most data teams in 2026 it cuts compute requirements significantly while delivering comparable results for task-specific adaptation.
Embedding model fine-tuning. Often overlooked: fine-tuning the embedding model in your RAG pipeline, rather than the generation model, improves retrieval for domain-specific terminology. This is frequently a higher-ROI intervention than fine-tuning the generator, and costs less.
Limitations and Real Failure Modes
RAG fails when:
- Source data is ungoverned. Stale, contradictory, or unclassified documents produce confident wrong answers. The retrieval algorithm is not the problem. The data is.
- Chunking strategy is wrong. Splitting documents at arbitrary character counts breaks logical context. Answers degrade when the model retrieves half an argument.
- Retrieval quality is not evaluated separately from generation quality. Teams that only measure final output quality miss poor retrieval as the root cause.
- Latency budgets are tight. Each query requires an embedding call and a retrieval round-trip before the generation call. For latency-sensitive applications, this adds meaningful overhead.
Fine-tuning fails when:
- The problem is knowledge, not behavior. A fine-tuned model will produce wrong facts with perfect formatting. Formatting correctness is not accuracy.
- Training data quality is insufficient. Poor-quality training examples produce worse behavior than the base model. Many teams discover this after the training cost is already spent.
- Catastrophic forgetting occurs. Fine-tuning on a narrow task can degrade the model's general capabilities. LoRA-family methods largely address this, but it remains a risk with full fine-tuning.
- Requirements change. A fine-tuned model is frozen at training time. If your task, format requirements, or domain language shifts, you retrain and pay again.
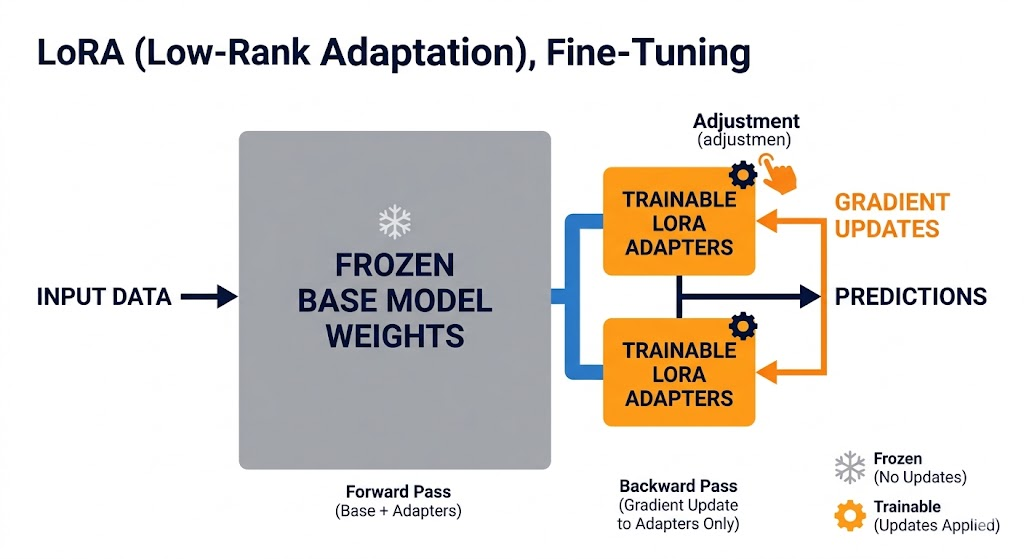
How They Compare
| Dimension | RAG | Fine-Tuning |
|---|---|---|
| What it fixes | Stale or missing knowledge | Inconsistent behavior, format, tone |
| Knowledge updates | Immediate (re-index documents) | Requires retraining |
| Minimum data required | None (can start with one document) | ~500 quality labeled examples |
| Setup time | Days to weeks | Weeks (including data prep) |
| Per-query cost | Higher (longer prompts) | Lower (shorter prompts) |
| Upfront cost | Low | $300–$30,000+ depending on approach |
| Hallucination risk | Lower (grounded in source docs) | Higher for out-of-distribution queries |
| Auditability | High (can cite source documents) | Low (knowledge is in weights) |
| Data privacy | Data stays in your infrastructure | Training data leaves your environment (if using API provider) |
| Latency | Higher (retrieval round-trip) | Lower (no retrieval step) |
Where competitors sit: Prompt engineering with long-context models is a third option both articles and teams frequently skip. If your entire knowledge base fits within roughly 200,000 tokens, injecting it directly into a long context window is faster to ship and often cheaper than building retrieval infrastructure. Evaluate this before building either RAG or fine-tuning pipelines.
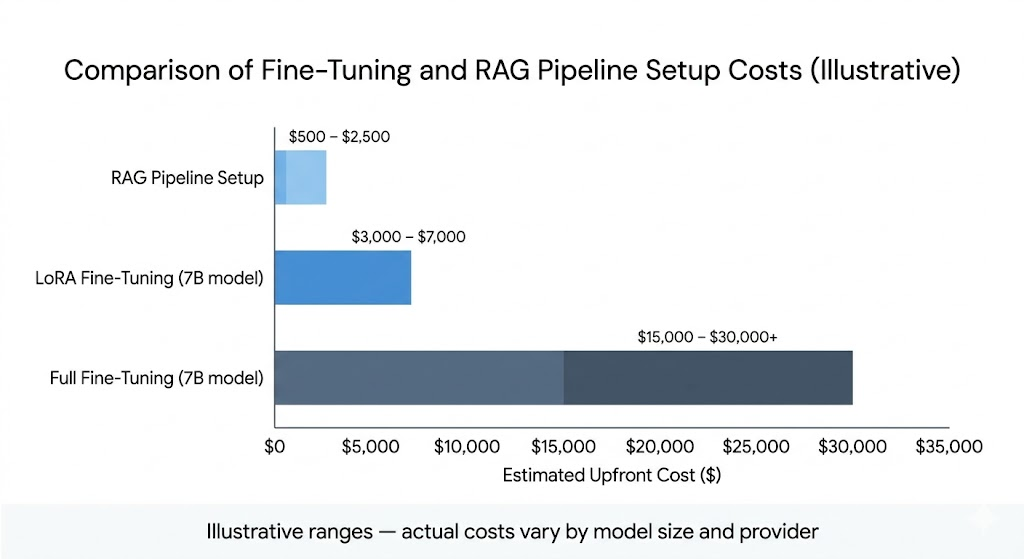
Pricing and Total Cost of Ownership
RAG
Ongoing costs are: vector database hosting (typically $0–$70/month for small-to-medium collections on managed services), embedding API calls, and LLM inference with longer prompts. The upfront cost is engineering time chunking strategy, retrieval pipeline setup, and evaluation. Expect 2–4 weeks of engineering work for a production-quality implementation.
The hidden cost most teams miss: data preparation and governance. Cleaning, classifying, and maintaining the knowledge base is an ongoing operational cost that does not appear in infrastructure pricing.
Fine-Tuning
Compute costs in 2026 using QLoRA on a single GPU:
- 7B model, QLoRA, single A100: $10–$20 in GPU compute for a training run (A100 instances available from ~$0.44/hr on spot markets)
- Full project cost including data prep and 3–5 iterations: typically $300–$3,000 for LoRA approaches on open-source 7B models
- Via API providers: GPT-4o fine-tuning runs $25 per million training tokens on OpenAI; open-source 7B models run from $0.48 per million tokens on providers like Together AI
The costs that consistently exceed initial estimates: data curation (typically 20–40% of total project cost), iteration cycles (the first run rarely ships to production), and ongoing retraining (production models drift and need updates every 3–6 months).
A useful break-even check: if fine-tuning lets you remove a 400-token system prompt from every request, and you're running 10,000 requests per day at $0.30 per million input tokens, you save roughly $43/month. A $1,000 fine-tuning job pays for itself in about two years at that volume. At 100,000 requests per day, it pays for itself in under three months. Know your volume before committing.
Who Should Use Each Approach
RAG is the right starting point if:
- Your knowledge changes frequently (pricing, policies, documentation, regulations)
- You need source attribution for compliance or trust
- Your data is sensitive and cannot enter a third-party training pipeline
- You are early in your AI deployment and need to ship and learn quickly
- You expect to swap the underlying base model as better options emerge
Fine-tuning is worth the investment if:
- Your failure mode is behavioral: wrong format, inconsistent tone, poor task adherence
- Your task is narrow, well-defined, and stable (fixed classification schema, specific output format)
- You have 500+ high-quality, representative training examples from real production traffic
- You have high request volume where per-token savings justify the upfront cost
- Latency is non-negotiable and retrieval round-trips are too slow
Neither is the right first step if:
You have not yet tested whether aggressive prompt engineering solves the problem. A well-written system prompt with clear instructions, examples, and output format specifications fixes a surprisingly large percentage of production issues. It costs nothing and ships in hours. Start there.
Practical Implementation Tips
1. Diagnose before you build. Run your base model with a carefully crafted prompt on 100 real examples. Categorize failures into two buckets: wrong facts (knowledge problem → RAG) and wrong behavior (behavior problem → fine-tuning). The bucket with more failures tells you where to start.
2. Check your context window budget first. If your entire knowledge base fits within the model's context window, try long-context injection before building retrieval infrastructure. Skip a month of engineering work if it works.
3. Treat retrieval quality as a separate metric. In RAG systems, measure precision and recall at the retrieval layer independently from final generation quality. Poor final answers caused by poor retrieval will not be visible if you only measure end-to-end output quality.
4. For RAG, invest in chunking strategy before embedding model selection. Chunking errors splitting logical units at arbitrary boundaries cause more retrieval failures than embedding model choice. Get chunking right first.
5. For fine-tuning, start with 200 manually reviewed examples, not 2,000 synthetic ones. Data quality dominates quantity for task-specific fine-tuning. Review every training example yourself before running a job.
6. Consider fine-tuning your embedding model before your generation model. For domain-specific terminology, a fine-tuned embedding model improves RAG retrieval quality at lower cost than fine-tuning the generator. Most teams skip this step.
7. Build evaluation before you build the pipeline. Automated evals LLM-as-judge or human evaluation on a held-out test set are the only way to know if your changes are improvements or regressions. Teams that skip evals ship degraded models and do not find out until user complaints arrive.
8. Plan for hybrid from the start. Design your architecture so RAG and fine-tuning can coexist. The typical production pattern is a fine-tuned model for behavioral consistency with a retrieval layer for factual grounding. Architecting them as incompatible alternatives creates expensive rework later.
Conclusion
The RAG vs fine-tuning decision is straightforward once you stop treating it as a technology preference and start treating it as a diagnostic tool. What is actually failing? Identify whether you have a knowledge problem or a behavior problem, and the architecture choice follows directly.
For most data teams in 2026, RAG is the right starting point. It ships faster, costs less to iterate, keeps your knowledge base current, and provides the auditability that compliance-conscious organizations increasingly require. Fine-tuning earns its cost in specific, well-defined scenarios: narrow tasks with stable requirements, high-volume applications where per-token economics matter, and situations where the base model's behavioral limitations are genuinely blocking production quality.
Where teams consistently get this wrong is by skipping the diagnostic step and defaulting to whichever approach feels more sophisticated. Fine-tuning on a knowledge problem is an expensive way to produce a model that formats incorrect answers consistently. RAG on a behavior problem is a retrieval pipeline that retrieves the right documents and still outputs the wrong format. Do the diagnosis first. Build second.
FAQ
Does fine-tuning eliminate hallucinations? No. Fine-tuning adjusts behavior, not factual knowledge. A fine-tuned model will still hallucinate confidently on topics not covered by its training data, often with better formatting. For factual accuracy, RAG is the more reliable intervention because responses are grounded in retrieved source documents.
How much training data does fine-tuning actually require? The practical minimum is around 500 high-quality examples. Most production fine-tuning jobs use 2,000–10,000 examples. Quality matters more than quantity 500 carefully curated examples from real production traffic consistently outperform 5,000 synthetically generated ones.
Can I use RAG and fine-tuning at the same time? Yes, and most mature production systems do. The standard pattern is a fine-tuned model for behavioral consistency and output format, with a RAG layer providing current factual knowledge. They address different failure modes and are architecturally compatible.
What if my knowledge base is small do I still need RAG? Not necessarily. If your entire knowledge base fits within roughly 200,000 tokens, injecting it directly into a long-context window can be simpler, faster, and cheaper than building retrieval infrastructure. Evaluate long-context injection before committing to a RAG architecture.
How often does a fine-tuned model need retraining? Production models typically need updates every 3–6 months as underlying data drifts and better base models release. High-stakes or rapidly-changing domains may require monthly cycles. This ongoing retraining cost should be factored into any fine-tuning business case upfront.