Data governance has crossed a threshold. It is no longer a documentation exercise or a committee driven policy layer. In 2026, governance is an operational control plane for data and AI systems one that regulators, auditors, and customers expect to function continuously, not just during reviews.
Three forces drive this shift:
- Regulatory convergence. Privacy law, AI regulation, and security standards now overlap at the data layer. Compliance failures are increasingly systemic, not isolated.
- AI native data flows. Training pipelines, feature stores, and inference telemetry blur traditional boundaries between analytics and production systems.
- Automation pressure. Manual governance cannot scale with streaming data, federated architectures, or rapid model iteration.
Frameworks like GDPR, the EU AI Act, and ISO/IEC 27001 are often treated separately. In practice, they impose shared requirements: traceability, accountability, and demonstrable control.
A 2026ready governance framework treats compliance as an emergent property of well instrumented systems not as an after the fact reporting task.
From Principles to Executable Controls
Abstract principles fail. Here’s what actually matters in 2026:
Lineage is non negotiable, but it’s not the whole story.
Lineage traces how data moved. Governance enforces why it’s allowed to move. You need both. The mistake most organizations make: they build beautiful lineage systems but have no controls sitting on top of them. Lineage without enforcement is auditability theater.
In practice: When someone queries a dataset containing PII, governance intercepts that query, checks the requestor’s role, applies masking rules, logs the access, and only then executes. Lineage records which data was accessed; governance ensures only authorized people accessed it.
Ownership must be unambiguous, or it disappears.
“Data governance committee” is governance graveyard speak. In 2026, every dataset, model, and feature has a named owner typically a domain team, not a central function. That owner is accountable for:
- Data quality and freshness
- Policy compliance
- Incident response
- Change requests
Central governance teams set standards (e.g., “all PII must be masked”), but domain owners enforce them (applying masking rules to their specific datasets).
In practice: A fintech company’s lending team owns the training dataset for their credit model. They define feature versions, manage consent records, set retention policies. Central governance audits their work and escalates violations. Without clear ownership, compliance becomes nobody’s problem.
AI systems need governance at every stage not just deployment.
Models aren’t data warehouses. They transform, combine, and infer from data continuously. A 2026 framework governs:
- Training data: Provenance verification, bias assessment, consent tracking, immutable snapshots for auditability.
- Features: Versioned definitions with lineage back to raw sources. Feature stores act as the control point.
- Models: Approval gates tied to risk classification. What triggers an audit? High risk lending models trigger more controls than low risk recommendation models.
- Inference: Logging of inputs and outputs (with privacy protections). Outputs that re enter as training data inherit original consent constraints.
The compliance risk is rarely the model itself ,it’s opaque data reuse across iterations.
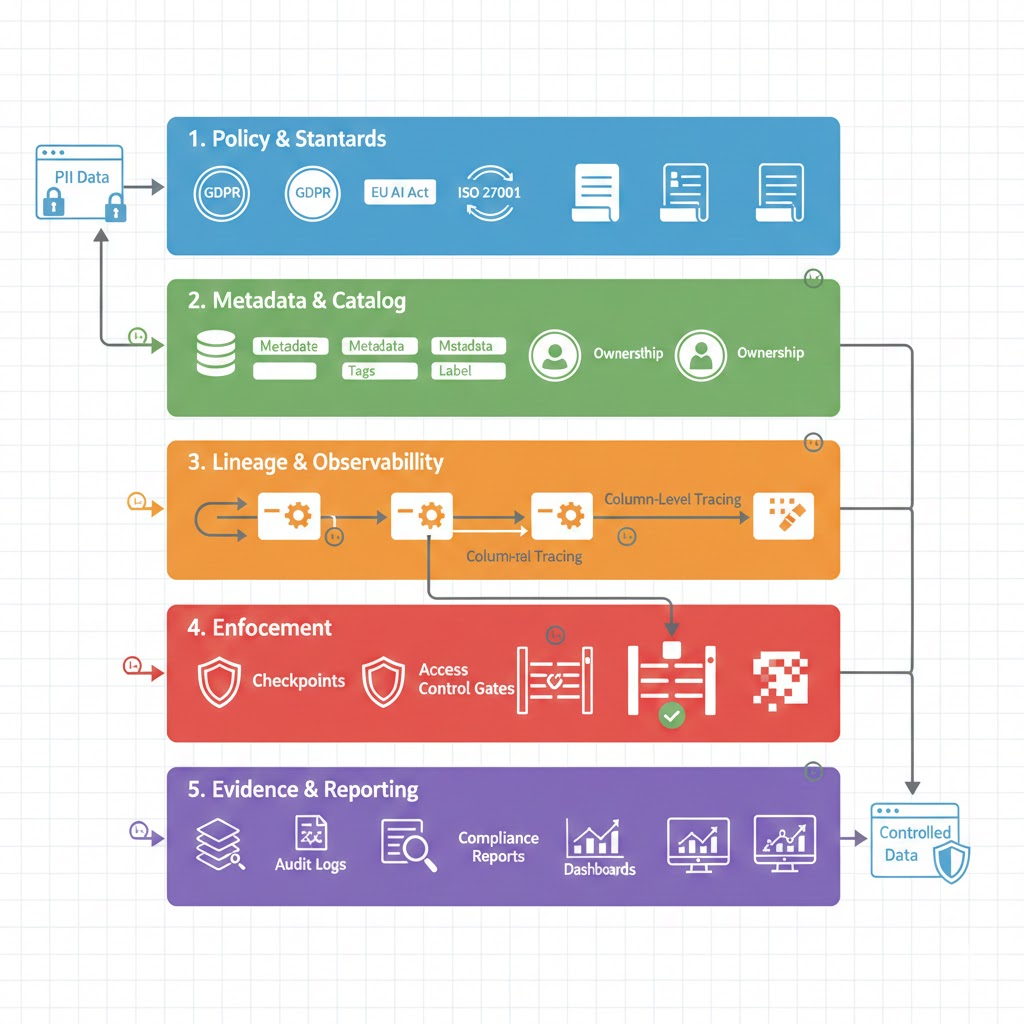
The Control Plane: Five Layers
Governance becomes real when mapped to architecture. A working framework has five layers:
Layer 1: Policy & Standards
Regulatory requirements translate into internal rules: data classification (public, internal, sensitive, restricted), retention limits, acceptable use, and AI risk categories. Output should be machine readable (policy as code) wherever possible.
Example: “Restricted data (financial records, health information) must not be used in non critical models and must be deleted within 7 years.”
Layer 2: Metadata & Catalog
Technical, business, and operational metadata converge here: schemas, owners, sensitivity labels, quality metrics. This is discoverable and versioned. Tools like Atlan, Collibra, or Alation own this layer.
Example: A dataset is tagged as containing PII, owned by the lending team, classified as restricted, with a 7 year retention limit.
Layer 3: Lineage & Observability
Column level lineage, transformation logic, and model dependencies are captured automatically. This layer supports impact analysis (“if we delete this field, which models break?”), consent propagation (“this data was collected under consent type X, does this new use still fit?”), and breach response (“which records were affected?”).
Example: Feature X came from table Y on timestamp T, transformed by job Z, used in model M. Lineage traces this deterministically.
Layer 4: Enforcement
Access controls, masking, encryption, and purpose limitation are enforced at query time or pipeline execution not manually reviewed later. This is where governance moves from visibility to control.
Example: A data scientist queries the lending dataset. The enforcement layer checks their role (can they access restricted data?), applies column masking (hide SSN, mask account numbers), logs the access, and returns results only if compliant.
Layer 5: Evidence & Reporting
Compliance artifacts are generated continuously: who accessed what, which model used which data, whether controls were applied. This feeds audit reports and incident investigations.
Example: “On date X, user Y accessed Z records from the lending dataset. Masking was applied to columns A and B. Access was logged and flagged for quarterly review.”
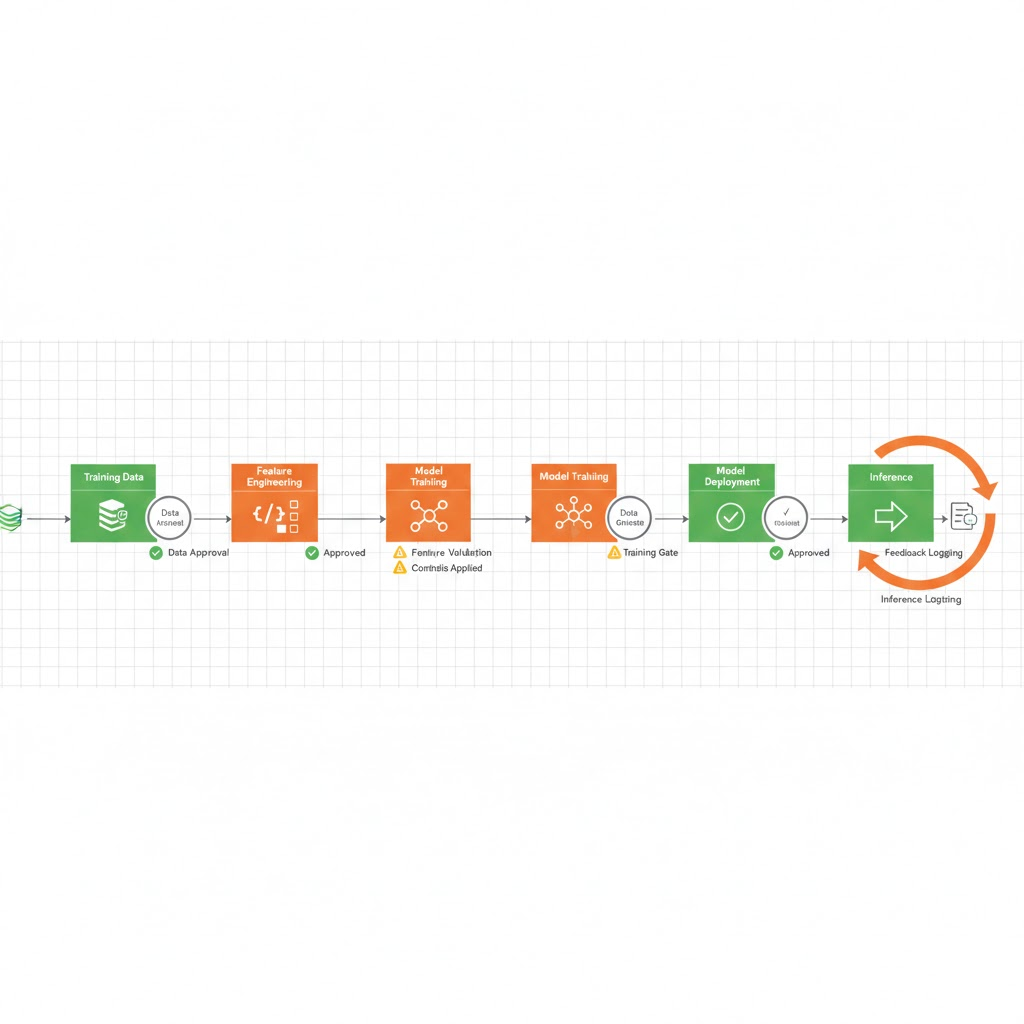
Real World Scenario: How This Works
A fintech company is building a credit risk model. Without a 2026 framework, here’s what typically fails:
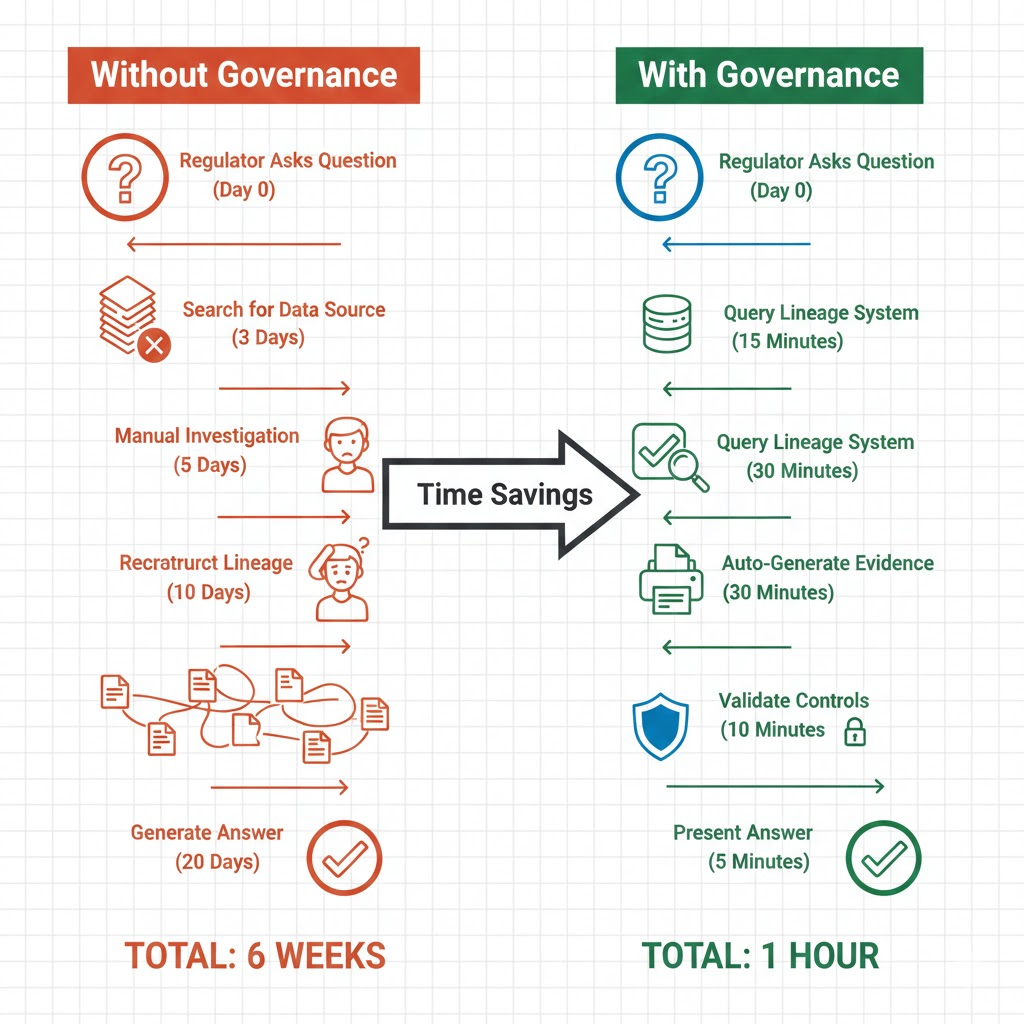
Without governance:
- Training data sourced from multiple APIs and internal databases; provenance unclear.
- Data scientist applies transformations in notebooks; no audit trail.
- Model trained on 500K records; nobody knows which individuals, what consent applies, retention rules.
- Model deployed; inference logs generated but not connected to training data.
- Regulator asks: “Which records trained this model?” Answer: unclear. Investigation takes 6 weeks.
With a 2026 framework:
- Policy phase: Central governance defines that credit models are high risk, require provenance verification, and must retain training data for 7 years with quarterly audits.
- Metadata phase: Each source system registers datasets in the catalog: consent type, retention policy, owner. The lending team defines their risk classification.
- Lineage phase: Training data is versioned (hash based). Transformations are logged (cleaning rules, feature engineering, sampling logic). Model training emits metadata: dataset version, feature set version, model version, metrics.
- Enforcement phase: When the model is deployed, inference logging is configured. Each prediction includes feature values and timestamp. If inference reveals suspicious patterns (e.g., systematic bias in approvals by ZIP code), the system flags it.
- Evidence phase: Regulator asks: “Which records trained this model?” Answer: available in 1 hour. “Show me bias analysis.” Answer: automated report generated from inference logs. “Can you delete individual X’s data?” Answer: traced through lineage, deletion confirmed.
Timeline: 1 hour instead of 6 weeks. Cost of compliance: front loaded engineering, then marginal operational overhead.
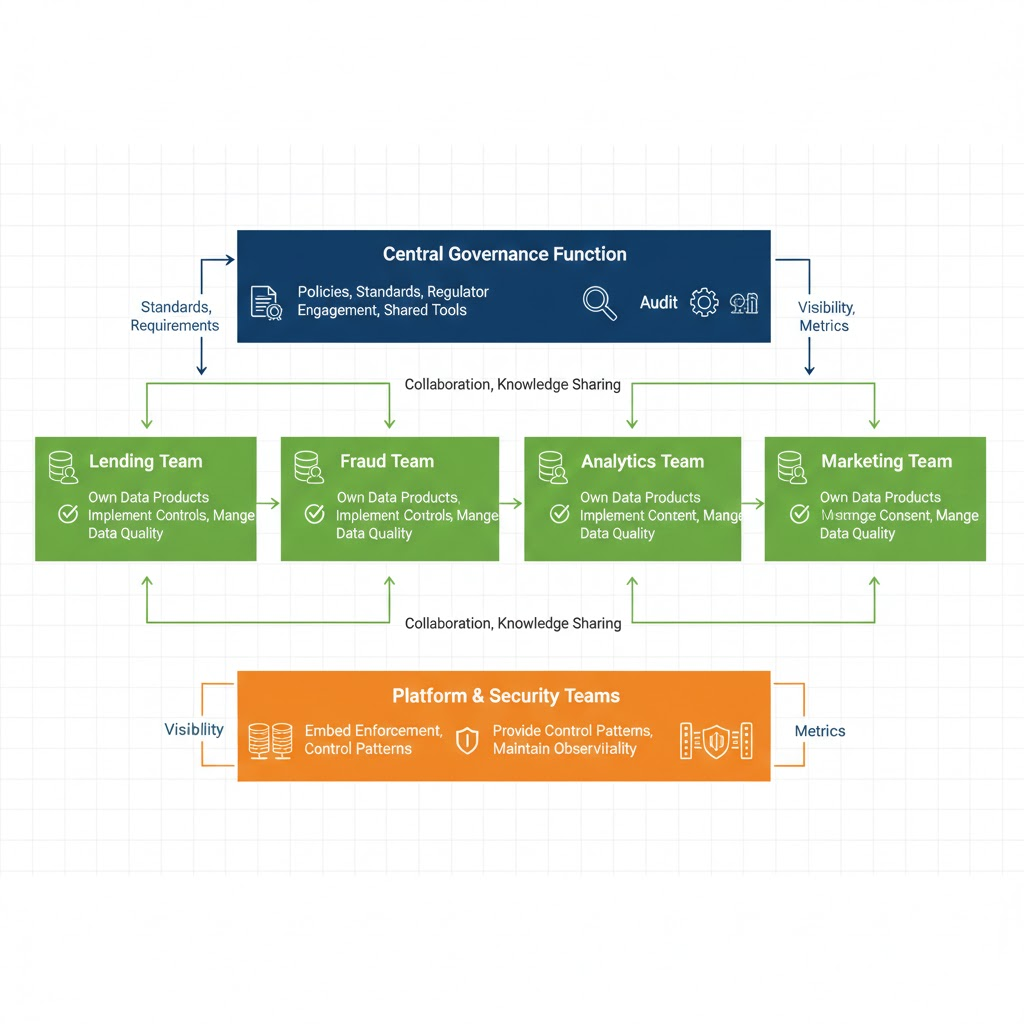
Operating Model: Who Owns What
Governance fails when ownership is unclear. A 2026 operating model typically has three layers:
Central Governance Function
- Defines policies (data classification, risk thresholds, retention rules)
- Owns regulator engagement and audit coordination
- Maintains shared tooling (catalogs, lineage platforms, enforcement engines)
- Sets standards (e.g., “all PII must be encrypted at rest”)
Domain Data Owners
- Accountable for specific datasets and models (lending team owns credit models; fraud team owns fraud detection)
- Implement controls in their domain (apply masking rules, set access policies, manage consent records)
- Respond to incidents and change requests
- Own the data quality and timeliness
Platform & Security Teams
- Embed enforcement into infrastructure (data warehouses, feature stores, ML platforms)
- Provide reusable control patterns (masking templates, access policy engines)
- Maintain observability (who accessed what, which controls were applied)
This federated model reduces bottlenecks while preserving consistency. The non negotiable requirement: transparency. Central teams must see control effectiveness without blocking delivery.
Implementation Roadmap: 12-18 Months
Phase 1: Baseline (Months 0–3)
- Inventory critical datasets, pipelines, and models
- Establish data classification and ownership
- Identify regulatory overlaps (GDPR + EU AI Act + industry specific rules)
- Identify high risk gaps (models without training data documentation, PII without access controls)
Success metric: You can answer “which systems are high risk?” and “who owns them?”
Phase 2: Instrumentation (Months 3–9)
- Deploy automated lineage (capture metadata as pipelines execute)
- Integrate access controls and masking into platforms (start with one high risk system)
- Standardize evidence collection (logging, audit trails)
- Choose tooling: Atlan or Alation for catalog/metadata, custom Kafka producers or managed services for lineage, enforcement via Snowflake/Databricks policies
Success metric: One high risk model has complete lineage and access controls. Auditor can trace from raw data to model output.
Phase 3: AI Governance Extension (Months 6–12)
- Apply governance controls to training and inference workflows
- Introduce model approval gates (high risk models require compliance sign off before deployment)
- Implement monitoring for unexpected data usage or model drift
- Document feature lineage (where do features come from? which models use them?)
Success metric: Models are deployed with approved training data, features are versioned and tracked, inference logs are governed.
Phase 4: Continuous Assurance (Months 12+)
- Shift from point in time audits to continuous compliance monitoring
- Use compliance metrics to drive improvements (e.g., reduce data access latency, improve masking coverage)
- Prepare governance for regulatory change without architectural rewrites
Success metric: Compliance is observable in real time dashboards. Incidents are detected and resolved before auditors ask.
Common Implementation Mistakes
- Starting with tools instead of operating model. You buy a gorgeous catalog platform before deciding who owns data. Then the tool sits empty. Define ownership first.
- Treating lineage as separate from enforcement. Beautiful lineage dashboards with no controls on top are expensive theater. Lineage is only valuable when tied to access policies and masking rules.
- Centralizing everything. Central governance teams trying to own every data product kill velocity. Federate ownership to domain teams; centralize standards.
- Forgetting about inference. Most governance stops at training. In 2026, inference is the risk surface. Who sees model inputs and outputs? How are they logged? How is feedback managed?
- Assuming compliance is static. Regulations change (August 2026: EU AI Act obligations shift). Your governance framework must evolve without requiring architectural rewrites.
The Honest Assessment
A 2026 data governance framework is not an org chart or a policy document. It is a set of automated controls embedded in infrastructure, enforced continuously, and validated by machine verifiable evidence.
Organizations that treat governance as policy exercise will fail audits and pay fines.
Organizations that embed governance into architecture lineage, masking, access controls, logging will move faster, audit confidently, and respond to incidents in hours instead of weeks.
The upfront investment is real (6–18 months of engineering). The payoff is compounding: reduced incident response time, eliminated surprise regulatory findings, faster model deployment, and earned trust with regulators and customers.
Start with one high risk system. Build end to end governance. Then scale the pattern. That’s how 2026 ready organizations operate.