MLOps has evolved significantly. It’s no longer just “CI/CD for models.” The real challenges now are traceability, control, and accountability across long-lived AI systems.
Regulatory requirements have changed everything. Rising model complexity and organizational sprawl have shifted priorities away from speed toward operational correctness. Teams must now balance velocity with governance.
This guide outlines MLOps best practices in 2026 that work in regulated, production-grade environments. The focus is on system properties—not tools—and the trade-offs you’ll face when models become critical infrastructure.
Best Practice 1: Treat MLOps as a Control Plane, Not a Pipeline
The most common MLOps failure? Over-investment in pipelines with under-investment in control planes.
Understanding the Difference
Pipelines move artifacts. They automate training and deployment.
Control planes explain, constrain, and audit artifacts. They answer critical questions: Why is this model here? Who approved it? What data trained it?
Consider this: If a regulator asks “why is this model in production?”, the answer cannot be “because the job ran.” You need documented reasoning, approval chains, and provenance.
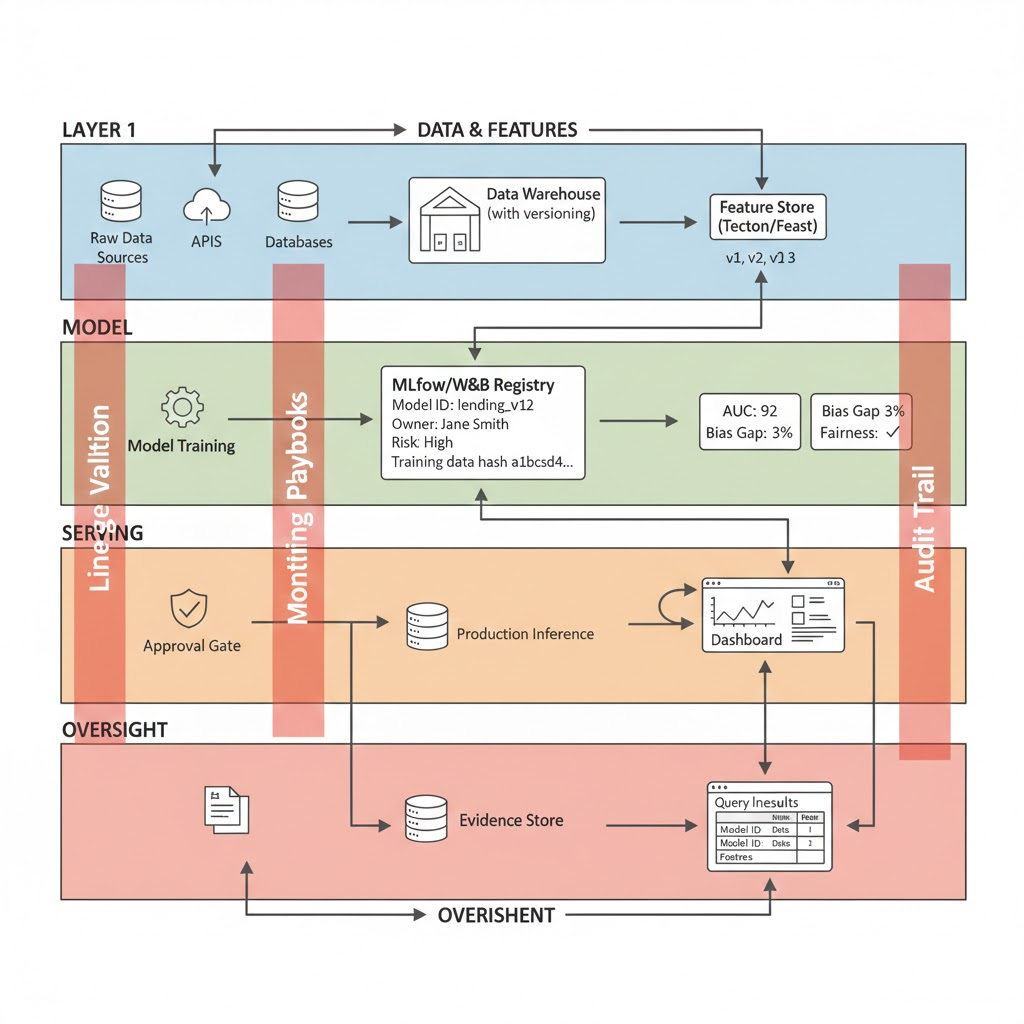
Mature organizations in 2026 use MLOps to coordinate:
- Data ingestion and transformation (with versioning)
- Feature computation (with immutable snapshots)
- Model training and evaluation (with full provenance)
- Deployment, routing, and rollback (with approval gates)
- Monitoring, incident response, and audit (with evidence trails)
What This Looks Like in Practice
A control plane typically includes:
Model Registry (MLflow, Weights & Biases, SageMaker):
- Stores model ID, version, and owner
- Records training data hash (not just the name)
- Tracks evaluation metrics and thresholds
- Documents the full approval chain
- Maintains deployment history
Feature Store (Tecton, Feast, Databricks):
- Enforces centralized feature definitions
- Locks feature versions to immutable snapshots
- Tracks lineage back to source data
- Stores governance metadata (retention, consent, sensitivity)
Orchestration Layer (Airflow, Dagster, Kubeflow):
- Logs who triggered what, when, and why
- Records data versions at each stage
- Documents transformation parameters and code versions
- Tracks success or failure with root cause information
Query Interface:
- Answers “Which models use dataset X?”
- Reconstructs “How was model Y trained on date Z?”
- Identifies “Which systems are affected if feature F is deprecated?”
Real Cost and Complexity
Infrastructure overhead: Expect 10-20% additional cost for metadata capture and storage.
Why teams accept this: A single incident investigation that would take weeks without a control plane justifies years of metadata costs.
Implementation timeline: Significant upfront effort (3-4 months for a medium-sized team). However, adding new models becomes fast after initial setup.
Adoption challenge: Engineers used to “train and ship” will initially resist. Prove value early by showing one incident where control plane metadata resolved the issue in hours instead of weeks.
Best Practice 2: Make Data Lineage a First-Class Runtime Concern
Data lineage is now non-negotiable for any AI system touching personal data, financial decisions, safety-critical workflows, or regulated outputs.
Compliance with GDPR, the EU AI Act, and ISO/IEC 42001 requires provable traceability. You must be able to trace from output back to source data.
Why Runtime Lineage Matters
Lineage captured after the fact is unreliable. A feature computation that succeeded months ago might have different semantics today. Training data becomes inaccessible. Investigators can’t reconstruct what happened.
Best practice in 2026: Capture lineage at execution time, immutably.
This means:
- Dataset versions are immutable and content-addressed
- Feature transformations are logged with code and parameters
- Training runs bind exact data hashes, not just dataset names
- Inference events reference the model version and feature snapshot used
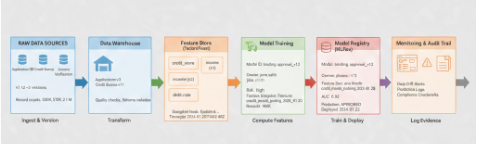
Implementation Pattern: Step by Step
Dataset versioning:
datasets:
applications:
v1: created 2024-01-10, hash: a1b2c3d4..., records: 500K
v2: created 2024-01-15, hash: d4c3b2a1..., records: 510K
credit_bureau:
v1: created 2024-01-10, hash: x7y8z9w0..., records: 2.1M
Feature snapshot capture: When features are computed for training, store:
feature_snapshot:
id: "credit_model_training_2024_01_20"
features: [credit_score, income, debt_ratio, age]
source_versions:
- applications:v2
- credit_bureau:v1
snapshot_hash: "f9e8d7c6..."
timestamp: 2024-01-20T14:32:00Z
computed_by: feature_store:feast:v3.1
Training provenance:
model:
id: lending_approval_v12
training_data_hash: f9e8d7c6...
feature_snapshot_id: credit_model_training_2024_01_20
train_test_split: 80/20 with seed 42
code_version: git_commit_abc123def456
evaluation_date: 2024-01-20
training_records: 400K (of 510K, due to sampling)
deployed: 2024-01-22
Inference logging: When the model makes a prediction, log:
inference:
model_id: lending_approval_v12
inference_date: 2024-01-25T10:15:30Z
applicant_id: john_doe_12345
features_used: [credit_score:750, income:85000, debt_ratio:0.15, age:35]
feature_snapshot_id: credit_model_training_2024_01_20
prediction: APPROVED
confidence: 0.87
This enables you to answer: “Show me every decision this model made on Jan 25 using the Jan 20 feature snapshot, which came from datasets versions applications:v2 and credit_bureau:v1.”
Managing the Trade-Offs
Storage costs: Lineage metadata is modest. For 10K daily inferences, that’s ~5-20 MB per day. Over 7 years (GDPR retention), approximately 13-50 GB. This is manageable.
Latency impact: Logging adds microseconds to inference. Negligible for batch systems. For real-time inference, the delay is measurable but acceptable.
Operational complexity: This requires standardization across data systems, feature stores, model registries, and inference pipelines. Initial setup is non-trivial. Ongoing maintenance is manageable.
Best Practice 3: Separate Model Risk Management from Model Performance
Accuracy metrics alone are insufficient in 2026. High-performing models are routinely blocked from deployment because they fail risk thresholds.
This isn’t inefficiency. It’s system design acknowledging that business impact ≠ ROC-AUC.
The Model Risk Management Lifecycle
Model risk management (MRM) operates as a parallel workflow with independent gates.
Stage 1: Pre-Training (Scoping)
First, define intended use: “This model approves credit for applicants age 18-75, income >$30K”
Identify constraints: “Cannot use ZIP code as proxy for race”
Specify scope: “US applicants only”
Stage 2: Model Development
Train the model on evaluation data.
Run bias audits: Does approval rate differ by demographic group?
Stress test: What happens with out-of-distribution inputs?
Document assumptions: “Training data skews toward urban applicants”
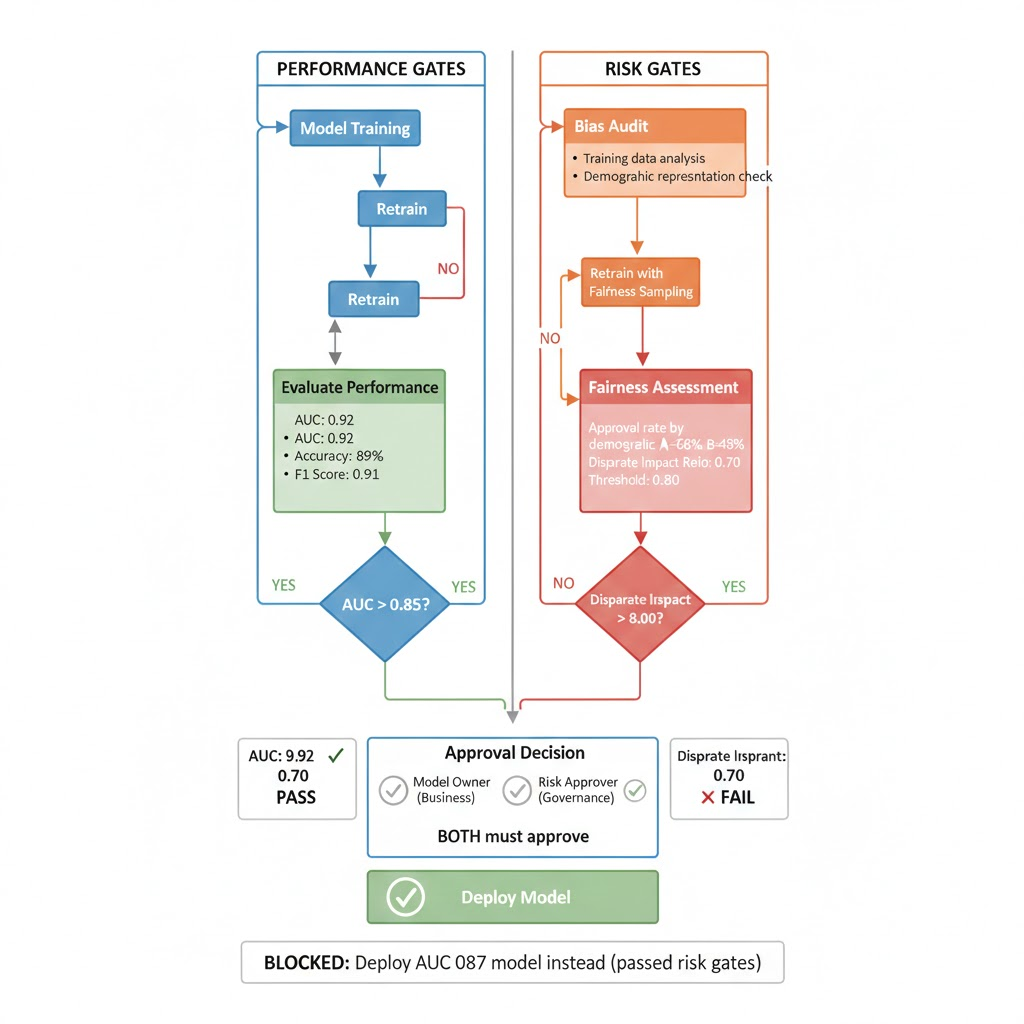
Stage 3: Risk Assessment Gate (Independent of performance gate)
Performance gate: “AUC > 0.85?” (Engineer responsibility)
Risk gate: “Bias gap < 5%? No systematic discrimination? Human override path defined?” (Risk approver responsibility)
Stage 4: Approval
Model owner approves on business grounds.
Risk approver approves on governance grounds.
Both must sign off. Either can block deployment.
Stage 5: Post-Deployment Monitoring
Continuous monitoring of bias, not just accuracy.
Alert if approval rate diverges by demographic group.
Automated escalation to risk team if guardrails are violated.
Real Example: When Risk Gates Block Deployment
Credit approval model (Jan 2024):
Training performance: AUC 0.92 (excellent)
Risk assessment results:
- Overall approval rate: 65%
- Approval rate for demographic A: 68%
- Approval rate for demographic B: 48%
- Disparate impact ratio: 0.70 (threshold is 0.80)
- Result: RISK GATE BLOCKS DEPLOYMENT
Engineer response: Retrain with fairness-aware sampling.
New model performance: AUC 0.87 (dropped 5 points)
Updated risk assessment:
- Overall approval rate: 63%
- Approval rate for demographic A: 63%
- Approval rate for demographic B: 62%
- Disparate impact ratio: 0.98 (passes)
- Result: RISK GATE APPROVES
Final decision: Deploy AUC 0.87 model (not the higher-performing AUC 0.92 model) because it passed risk gates.
This is standard practice in 2026. High performance that violates fairness constraints is business liability, not victory.
Best Practice 4: Observability Must Extend Beyond Drift Metrics
Drift detection (data distribution shift) remains necessary but insufficient.
In production systems, the most damaging failures in 2025-2026 were not slow drifts. They were context breaks: changes in upstream semantics, policy constraints, or business rules.
What Signals Actually Matter
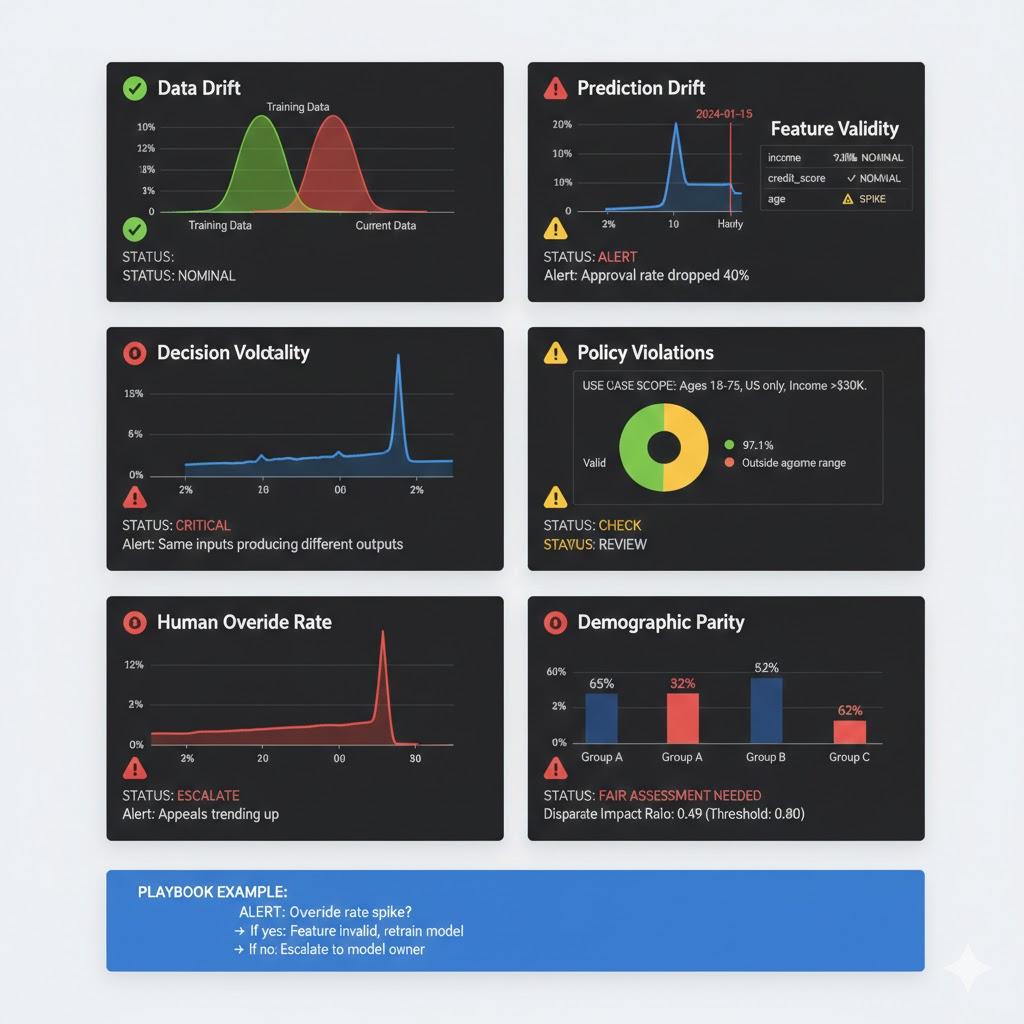
Traditional drift signals:
- Data drift: Input distributions shifting vs. training set
- Prediction drift: Output distribution changing over time
- Feature attribution drift: Which features matter now vs. at training?
Context signals (often missed):
- Feature validity: Null rates, value ranges, schema changes
- Decision volatility: Same input producing different outputs (suggests retraining or model instability)
- Policy violations: Model making decisions outside approved context
- Human feedback: Appeals, overrides, customer complaints trending up
Observability in Practice: Real Alert Example
Alert: “Approval rate for applicants with income=$50-60K dropped from 45% to 12% in 72 hours”
Without strong observability:
- Team checks accuracy metric: still 0.91, no change
- Team checks data drift: inputs look similar
- Team shrugs and deploys a monitoring dashboard
- Real issue goes undetected for weeks
With strong observability:
- Alert triggers because decision volatility threshold crossed
- Team queries lineage: which applicants are affected?
- Team checks feature validity: is income field still populated correctly?
- Root cause found in 2 hours: upstream system changed income calculation logic
- Team retrains model on corrected data or routes traffic to previous model version
Building Observability: Minimum Viable Set
Start with these 5-7 metrics:
- Null rate per feature: If nulls spike, something upstream broke
- Value range per feature: Alert if feature exceeds historical min/max
- Prediction distribution: Alert if output distribution shifts (e.g., approval rate drops)
- Human override rate: Alert if overrides spike (model making questionable decisions)
- Latency percentiles: Alert if p99 latency increases (signals downstream system issue)
- Demographic parity metrics: For regulated systems, alert if approval rate diverges by group
- Custom business metrics: For loan approvals, track approval amount average, rejection reason distribution
Connect each metric to a playbook. When this alert fires, here’s what you do. Without playbooks, alerts become noise.
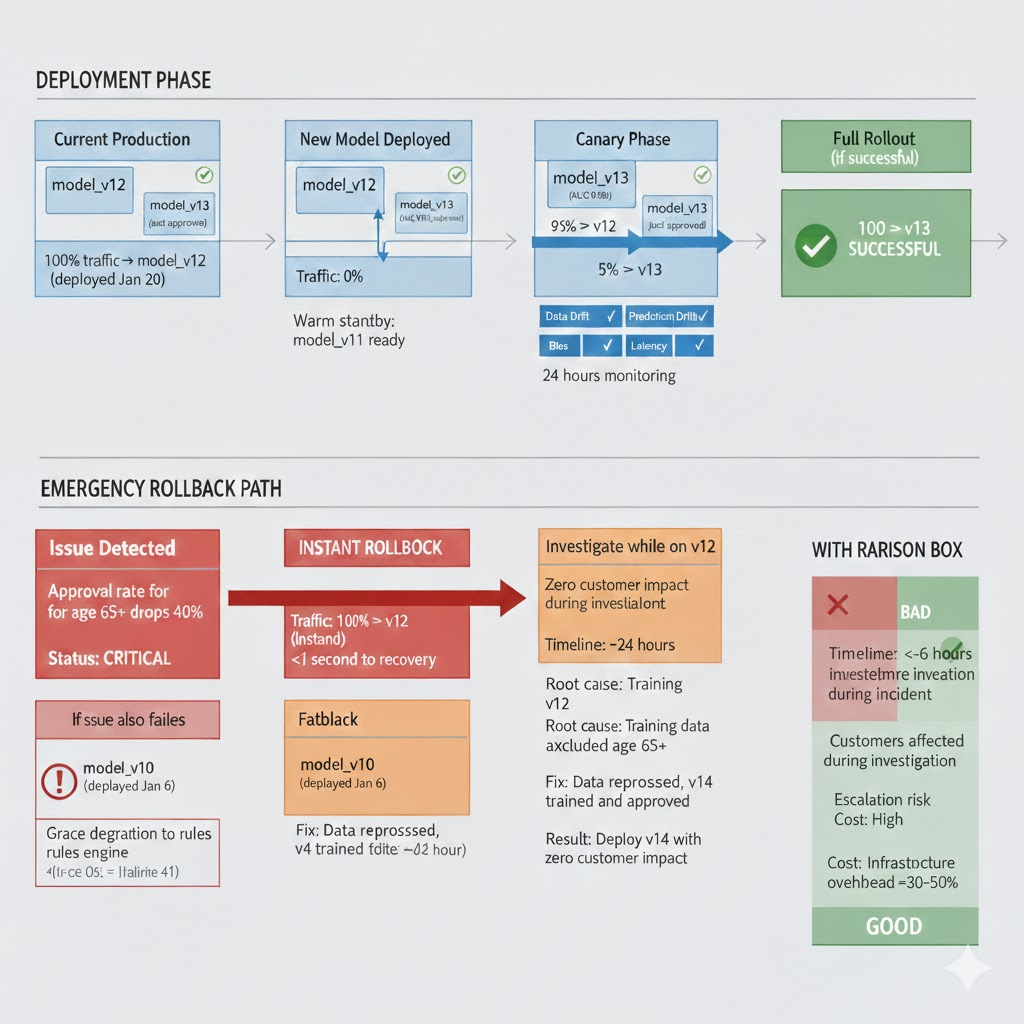
Best Practice 5: Design for Rollback, Not Just Retraining
Retraining is slow. Rollback is fast.
Resilient MLOps systems assume models will fail in unexpected ways. They prioritize reversibility.
Rollback Architecture That Works
Multi-model serving:
Current production: model_v12 (deployed Jan 20)
Warm standby: model_v11 (deployed Jan 13)
Cold backup: model_v10 (deployed Jan 6)
Traffic routing:
Normal state: 100% → model_v12
Issue detected: 100% → model_v11 (instant, <1 second)
Extended issue: Investigate while on v11, retrain, deploy v13
Feature flag–based disablement:
If model predictions are unavailable or questionable:
flag "use_ml_approvals" = false
Revert to rules engine:
- income > $50K and credit_score > 650: APPROVE
- income < $50K and credit_score > 700: REVIEW
- else: DECLINE
This maintains service while investigation happens.
Graceful degradation path:
Model latency spike? Don't return stale predictions.
Instead: Route to simplified heuristic or human review queue.
Better to slow down than make bad decisions fast.
Implementation Trade-Offs
Keep old models hot: Running two models in parallel increases infra cost 30-50%. However, this enables instant rollback.
Preserve feature schema compatibility: When you update features, ensure old models can still consume them. This requires feature versioning and careful schema evolution.
Avoid irreversible online learning: Bandit algorithms and online learning update model behavior continuously. If something goes wrong, you can’t revert. For high-risk systems, batch retraining is safer.
Real Example: Rollback in Action
Jan 25, 2024, 10 AM: New lending model deployed (v13, AUC 0.93, just approved)
11:30 AM: Alert fires: approval rate for applicants age 65+ dropped 40% (was 50%, now 10%)
11:45 AM: Team investigates. Root cause unclear (model looks fine on surface). Decision: trigger rollback.
11:47 AM: Traffic rerouted to model v12 (approved rate returns to 50%)
Afternoon: Investigation continues using v12 as stable baseline. Found: training data for v13 accidentally excluded applicants 65+ in one batch. Bug in data filtering logic.
Next day: Fix identified, data reprocessed, v14 trained and approved. Deployed with zero customer impact during investigation.
Without rollback architecture: Same incident would have required 4-6 hours of investigation with customers affected. Potential regulatory escalation. Reputation damage.
Best Practice 6: Align MLOps With Organizational Accountability
The final best practice is non-technical but decisive: someone must be accountable for each model in production.
The Accountability Model That Works
Model Owner (Business Accountability):
- Responsible for business outcomes
- Makes judgment calls on deployment timing
- Owns customer and regulator communication
- Example: Head of Lending, VP of Fraud Prevention
Technical Steward (Engineering Accountability):
- Responsible for system reliability, latency, and cost
- Owns monitoring, incident response, and optimization
- Maintains feature definitions and model registry
- Example: Senior ML Engineer, MLOps Lead
Risk Approver (Governance Accountability):
- Responsible for risk assessment and compliance
- Approves high-risk deployments
- Escalates incidents and documents deviations
- Example: Compliance Officer, Risk Manager
Critical point: All three roles persist beyond deployment. A model without active owners accumulates silently until it becomes a liability.
In 2026, regulators increasingly ask “Who approved this?” not “Which tool was used?”
Common MLOps Failures (And How to Prevent Them)
Even with best practices in place, predictable problems emerge.
Failure Mode 1: Control Plane Becomes Bottleneck
What happens: Model registry requires 5 approvals. Feature store has 2-week onboarding. Teams start shipping models outside the control plane.
Root cause: Control plane adds overhead perceived as slowing innovation.
Solution: Make low-risk models fast-track. Low-risk model (internal, reversible): 1 hour approval. High-risk model (customer-facing, regulated): 24 hours. Enable self-service feature creation with templates for pre-approved transformation types.
Failure Mode 2: Lineage Data Grows Unwieldy
What happens: After 6 months, lineage queries timeout. Storage bills spike. Teams stop querying lineage.
Root cause: Lineage capture was implemented without retention policies or query optimization.
Solution: Set retention upfront (7 years for regulated data, 2 years for non-regulated). Index lineage by model ID and date. Partition storage by time. Test query performance before deployment.
Failure Mode 3: Risk Gates Become Political
What happens: Every model is marked “high-risk” because stakeholders want oversight. Alternatively, marked “low-risk” because teams want faster deployment.
Root cause: Risk classification tied to organizational politics, not actual impact.
Solution: Define risk objectively. Consider (1) automation level (autonomous vs. human-in-loop), (2) affected population (1K users vs. 1M users), (3) reversibility (easy to undo vs. permanent). Make it measurable, not subjective.
Failure Mode 4: Observability Alerts Are Ignored
What happens: 200 alerts per week. Teams mute most. Real incidents go undetected.
Root cause: Too many signals, no playbooks, false positive rate too high.
Solution: Start with 3-5 critical signals. Write playbooks before deploying monitors. Measure alert precision (% that require action). Tune thresholds to 95%+ precision. Add signals incrementally.
Failure Mode 5: Rollback Path Is Untested
What happens: Incident requires rollback. Team discovers old model is incompatible with current features. Rollback fails. Hours of downtime.
Root cause: Rollback strategy defined but never tested in production.
Solution: Monthly “chaos engineering” drill: intentionally trigger a rollback. Measure time-to-recovery. Fix issues in low-pressure environment, not during crisis.
Real-World Implementation Story: Financial Services
A fintech company deploying ML across credit and fraud detection faced significant pressure in 2026: GDPR enforcement, EU AI Act implications, and internal audit expectations.
Starting State (Q3 2025)
- 23 models in production, half owned by “the team”
- Data lineage: manual spreadsheets
- Risk assessment: conducted once at deployment, never updated
- Observability: accuracy metrics only
- Recent incident: Bias in one model went undetected for 3 weeks
Implementation Timeline (Q4 2025 – Q1 2026)
Month 1: Control Plane Foundation
- Implemented MLflow model registry (1 FTE, 4 weeks)
- Assigned owners to all 23 models (RACI definition)
- Set risk classification for each model
Month 2: Lineage Capture
- Integrated feature store (Tecton) with training pipeline (2 FTE, 6 weeks)
- Instrumented inference logging to capture feature snapshots
- Established data retention policies (7 years for regulated data)
Month 3: Risk Management Gates
- Built independent risk assessment workflow (1 FTE, 4 weeks)
- Defined guardrails: bias gap < 5%, approval rate parity > 0.95
- Trained risk approver team
Month 4: Observability & Monitoring
- Deployed ML monitoring (1 FTE, ongoing)
- Wrote 5 core observability metrics and playbooks
- Set up incident alert routing
Month 5: Rollback & Resilience
- Multi-model serving infrastructure (0.5 FTE, 2 weeks)
- Tested rollback procedures (monthly chaos engineering)
- Documented graceful degradation paths
Results (End of Q1 2026)
| Metric | Before | After |
|---|---|---|
| Incident detection time | 3+ weeks | <4 hours |
| Incident resolution time | 2+ weeks | 1-2 hours |
| Audit readiness | Manual, 2 weeks | Automated, 1 hour |
| Model deployments/month | 3 | 12 |
| High-risk model deployment blocks | 0 | 2 |
Investment: ~6 FTE-months total (3-4 months for 2 engineers), ~$150-200K in tooling/infra
Payoff: Avoided regulatory fine (estimated $500K+), eliminated customer-visible incidents, enabled 4x faster deployments for low-risk models.
What Good MLOps Looks Like in 2026
Here’s what matters:
- Pipelines automate; control planes explain. You reconstruct what happened without asking engineers.
- Lineage is captured at runtime, not reconstructed. Immutable, queryable, auditable.
- Risk gates block high-performing models. Fairness and safety are non-negotiable.
- Observability tracks assumptions, not just accuracy. You know when context breaks.
- Rollback is faster than retraining. Multi-model serving is standard infrastructure.
- Accountability outlives deployment. Owners, stewards, and approvers remain accountable.
- Incidents are traced, not guessed. Lineage enables root-cause analysis in hours.
MLOps best practices in 2026 are less about speed and more about operational truthfulness. Systems that can explain themselves survive longer than systems that merely optimize.
Starting Point: Phased Rollout (6-9 Months)
If you’re implementing from scratch:
Phase 1 (Weeks 1-4): Model Registry + Ownership
- Deploy MLflow or equivalent
- Assign owner and risk classification to each model
- Success: Every model has a named owner
Phase 2 (Weeks 5-12): Lineage Foundation
- Instrument feature store for lineage capture
- Log training data hashes
- Success: You can answer “which data trained this model?”
Phase 3 (Weeks 13-20): Risk Management Gates
- Define risk assessment workflow
- Build CI gates blocking risky deployments
- Success: High-risk models require independent approval
Phase 4 (Weeks 21-28): Observability Signals
- Deploy 3-5 core observability metrics
- Write playbooks for each alert
- Success: Incidents detected in <4 hours
Phase 5 (Weeks 29+): Resilience & Rollback
- Implement multi-model serving
- Test rollback procedures
- Success: Rollback completes in <5 minutes
Don’t try everything at once. Phase 1 alone (model registry and ownership) provides 60% of the value.