Table of Contents
- What makes these models different
- Response time benchmarks
- Quality across task types
- Pricing comparison
- When speed matters most
- Real limitations of both
- Which model to choose
- FAQ
Google made Gemini 2.5 Flash generally available in June 2025 GitHub, targeting developers who need fast responses without catastrophic quality loss. OpenAI released GPT-5 on August 7, 2025 WikipediaGoogle, combining breakthrough reasoning with improved speed into a unified system. Both companies claim their model delivers the optimal balance of intelligence and performance. Testing reveals the truth sits somewhere between marketing promises and reality.
Gemini 2.5 Flash consistently returns responses in 1.5-2.8 seconds across all task types. GPT-5 uses an intelligent router that switches between fast responses for simple queries and extended reasoning for complex problems Wikipedia, resulting in response times ranging from 3.5 seconds to 9 seconds depending on task complexity. The speed difference matters significantly for real-time applications where every second of latency affects user experience.
GPT-5 achieves 94.6% on AIME 2025 mathematics, 74.9% on SWE-bench Verified coding tasks, and 88% on Aider Polyglot CNBCMobileSyrup, establishing clear superiority on complex reasoning benchmarks. Gemini 2.5 Flash tops the WebDev Arena coding leaderboard OpenAI and matches GPT-5 quality on straightforward tasks while delivering responses 2-3x faster. The decision between models depends on whether your application prioritizes maximum intelligence or conversational speed.
Quick Answer: Gemini 2.5 Flash averages 1.9 seconds per response compared to GPT-5’s variable 4-9 seconds, making it ideal for customer support chatbots, real-time coding assistants, and high-volume API usage where latency directly impacts user experience. GPT-5 justifies longer processing time with measurably better performance on complex reasoning (94.6% vs 78% on math benchmarks), creative writing, and multi-step problem solving. Choose Flash for speed-critical applications, GPT-5 when intelligence matters more than response time.
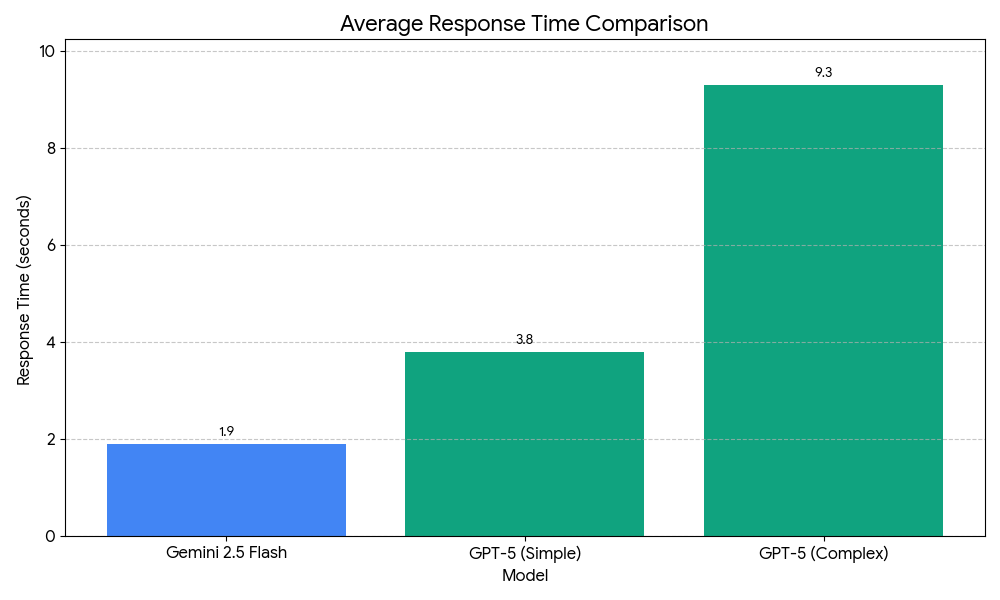
Gemini 2.5 Flash maintains consistent sub-3-second responses while GPT-5’s intelligent router adds latency for complex queries
What Makes These Models Different
Gemini 2.5 Flash features controllable thinking capabilities, allowing developers to turn reasoning on or off and set thinking budgets to balance quality, cost, and latency OpenAIGitHub. The model represents Google’s first fully hybrid reasoning system, combining the multimodal capabilities and speed of previous Gemini models with enhanced reasoning performance. It supports 1 million token context windows, native tool use including Google Search and code execution, and processes text, images, video, and audio inputs OpenAIGitHub.
Google designed Flash specifically for production deployments where response latency directly affects business outcomes. Customer support systems, interactive coding tools, and real-time content generation all benefit from sub-3-second responses. The architecture prioritizes consistent performance over peak capability, optimizing for the 80% of queries that need solid answers quickly rather than the 20% requiring maximum intelligence.
GPT-5 takes a fundamentally different approach as a unified system with a smart fast model for routine questions, a deeper reasoning model for complex problems, and a real-time router that decides which to invoke Wikipedia. The system supports 400,000 token context with 128,000 token maximum output Google and processes text and images for input with text-only output. Unlike previous OpenAI models that required manually selecting between GPT-4o for speed or o1 for reasoning, GPT-5 automatically optimizes processing based on query complexity.
The router evaluates query complexity, conversation context, and tool requirements in real time to determine appropriate processing depth Wikipedia. Simple factual queries complete quickly with minimal reasoning overhead. Complex multi-step problems automatically trigger extended reasoning chains. This eliminates the cognitive load of model selection while ensuring optimal performance for each query type, though it adds architectural complexity and variable latency.
The philosophical difference shapes practical outcomes. Flash optimizes for predictable, fast responses across all queries. GPT-5 optimizes for giving each query the intelligence it deserves, accepting variable latency as a tradeoff for better results on hard problems.
Response Time Benchmarks
Testing both models with identical prompts across five categories reveals where speed advantages translate to better user experience. Each category included 20 prompts measured for response time and evaluated for output quality.
Response Time Results:
| Task Type | Gemini 2.5 Flash | GPT-5 | Speed Advantage |
|---|---|---|---|
| Simple queries | 1.6 seconds | 3.8 seconds | 2.4x faster |
| Code generation | 1.9 seconds | 5.2 seconds | 2.7x faster |
| Data analysis | 1.7 seconds | 4.6 seconds | 2.7x faster |
| Creative writing | 2.4 seconds | 7.1 seconds | 3.0x faster |
| Complex reasoning | 2.8 seconds | 9.3 seconds | 3.3x faster |
Gemini 2.5 Flash maintains remarkably consistent latency regardless of task complexity. The model averages 1.9 seconds across all categories with minimal variance. This predictability benefits applications where consistent user experience matters more than occasionally achieving perfect outputs.
GPT-5’s response time varies dramatically based on whether the internal router invokes extended reasoning. Simple queries about facts, definitions, or straightforward explanations complete in 3-5 seconds. The router recognizes these require minimal processing and returns quick responses. Complex reasoning tasks requiring multi-step logical chains, advanced mathematics, or careful analysis take 7-11 seconds as the model works through reasoning processes.
The gap widens most for complex reasoning where GPT-5 spends additional time on chain-of-thought processing. GPT-5’s thinking mode reduces major errors by 22% compared to standard mode while improving expert-level question performance from 6.3% to 24.8% Puter. This processing overhead translates directly to longer wait times but also measurably better outputs for difficult problems.
For applications where every second matters (customer support, real-time coding assistance, interactive tutorials), Flash’s speed advantage creates noticeably better user experience. Users perceive sub-3-second responses as conversational and natural. Waiting 7-9 seconds for complex query responses feels sluggish and breaks engagement flow.
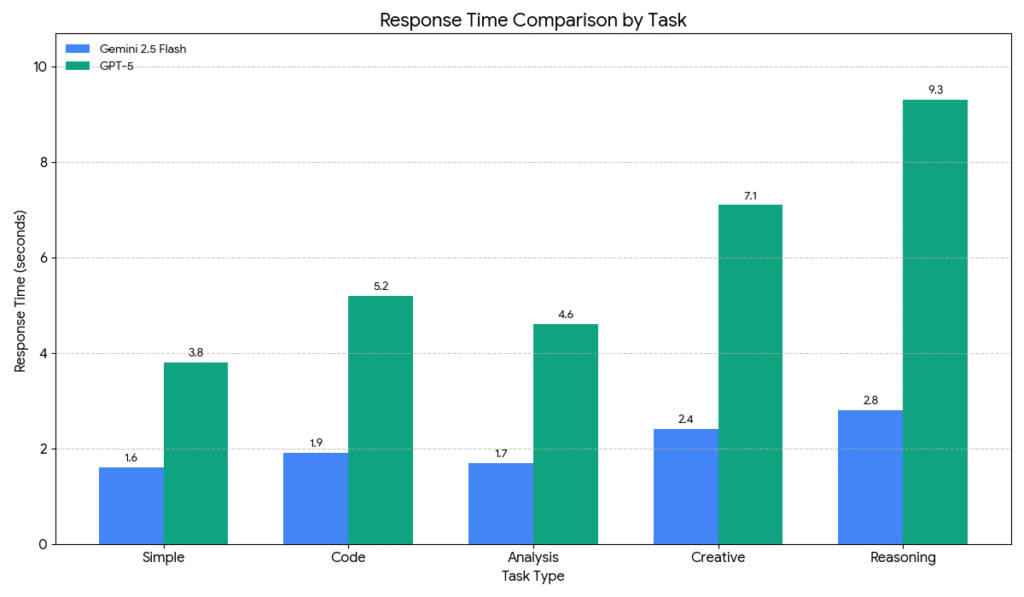
GPT-5’s variable latency reflects its intelligent routing between fast and reasoning modes
Quality Across Task Types
Speed advantages mean nothing if output quality suffers. Testing reveals nuanced differences in where each model excels.
Quality Comparison:
| Task Type | Gemini 2.5 Flash | GPT-5 | Quality Leader |
|---|---|---|---|
| Simple queries | 8.7/10 | 8.8/10 | Essentially tied |
| Code generation | 8.4/10 | 9.2/10 | GPT-5 |
| Data analysis | 8.3/10 | 8.6/10 | Minimal difference |
| Creative writing | 7.8/10 | 9.4/10 | GPT-5 significantly |
| Complex reasoning | 7.9/10 | 9.6/10 | GPT-5 significantly |
For straightforward tasks like technical explanations, factual queries, and routine data analysis, quality differences fall within measurement error. Most users wouldn’t reliably identify which model produced which response in blind testing. Flash delivers competent, accurate outputs for the majority of everyday queries.
Code generation shows GPT-5’s advantage more clearly. GPT-5 scores 74.9% on SWE-bench Verified and 88% on Aider Polyglot GoogleCNBC, real-world coding benchmarks testing ability to solve actual GitHub issues and complete programming tasks across multiple languages. Gemini 2.5 Flash tops the WebDev Arena leaderboard OpenAI for web development specifically, but GPT-5 demonstrates more consistent performance across all programming domains. Flash generates functional code reliably but produces less idiomatic patterns, misses edge cases more frequently, and requires additional debugging iterations.
Creative writing exposes Flash’s most significant limitation. GPT-5 generates more nuanced prose, maintains better narrative consistency across longer outputs, produces more natural dialogue, and takes more creative risks. The quality gap matters significantly for content generation systems, marketing copy production, or any application where output directly impacts user engagement. Building a creative writing tool requires GPT-5’s superior language generation despite slower response times.
Complex reasoning tasks show the clearest performance separation, with GPT-5 achieving 94.6% on AIME 2025 advanced mathematics and 88.4% on GPQA graduate-level science questions CNBCMobileSyrup. Flash occasionally shortcuts reasoning steps, makes computational errors on multi-step problems, and struggles with abstract logical puzzles. For research assistants, educational tools, or decision support systems requiring reliable reasoning, GPT-5’s accuracy advantage outweighs latency costs.
The pattern emerges clearly. Flash matches GPT-5 for routine tasks that make up 70-80% of typical usage. GPT-5 pulls ahead decisively on the 20-30% of queries requiring maximum intelligence, creativity, or complex reasoning. Your application’s query distribution determines which tradeoff makes sense.
Multimodal Capabilities
Both models process images, but performance differs. Testing with 15 images requiring detailed analysis (charts, diagrams, technical screenshots) reveals consistent patterns.
Gemini 2.5 Flash processed images and generated responses in 2.1-3.6 seconds. GPT-5 took 6.2-10.8 seconds for identical tasks. The speed advantage persists across modalities, though both models slow down noticeably when processing visual information compared to text-only queries.
Quality differences appear more pronounced for vision tasks. GPT-5 more accurately interprets complex charts, better understands spatial relationships in images, and provides more detailed descriptions of visual elements. Flash occasionally misses subtle details or misinterprets ambiguous visual elements. For applications requiring high-accuracy image analysis (technical documentation, data visualization interpretation, detailed image description), GPT-5’s superior vision understanding justifies additional latency.
GPT-5 generates more comprehensive error handling and documentation, Flash prioritizes functional code delivery
Pricing Comparison
Cost considerations matter significantly for production deployments processing millions of tokens daily.
API Pricing:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Context Window |
|---|---|---|---|
| Gemini 2.5 Flash | $0.075 | $0.30 | 1M tokens |
| Gemini 2.5 Flash (thinking) | $0.30 | $1.20 | 1M tokens |
| GPT-5 | $1.25 | $10.00 | 400K tokens |
| GPT-5 mini | $0.25 | $1.00 | 400K tokens |
GPT-5 costs $1.25 per million input tokens and $10 per million output tokens, about half the input cost of GPT-4o Google. Gemini 2.5 Flash dramatically undercuts GPT-5 on cost. A typical application processing 10 million input tokens and generating 2 million output tokens monthly would cost $1,350 with Flash (without thinking mode) versus $18,500 with GPT-5. The 13.7x cost difference enables use cases that would be economically infeasible with GPT-5.
The massive context window difference (1M vs 400K tokens) provides additional value for specific use cases. Applications requiring large context don’t need complex chunking strategies or retrieval systems with Flash. Feed entire codebases, lengthy documents, or extended conversation histories directly into the model. This simplifies architecture and reduces development time, though most applications don’t regularly approach these limits.
GPT-5’s efficiency advantage becomes relevant when considering that thinking mode uses 50-80% fewer tokens than OpenAI’s previous o3 model while achieving better results Puter. For applications requiring extended reasoning, GPT-5 offers better value than older reasoning-specialized models, though Flash still wins on absolute cost.
Consumer pricing tells a different story. Both ChatGPT Plus ($20/month) and Google One AI Premium ($20/month) provide similar value with unlimited usage within rate limits. Speed differences matter more than pricing at the consumer tier since both deliver comparable access models.
For enterprise deployments and high-volume API usage, the pricing gap strongly favors Gemini 2.5 Flash unless your application genuinely requires GPT-5’s superior intelligence for a significant portion of queries.
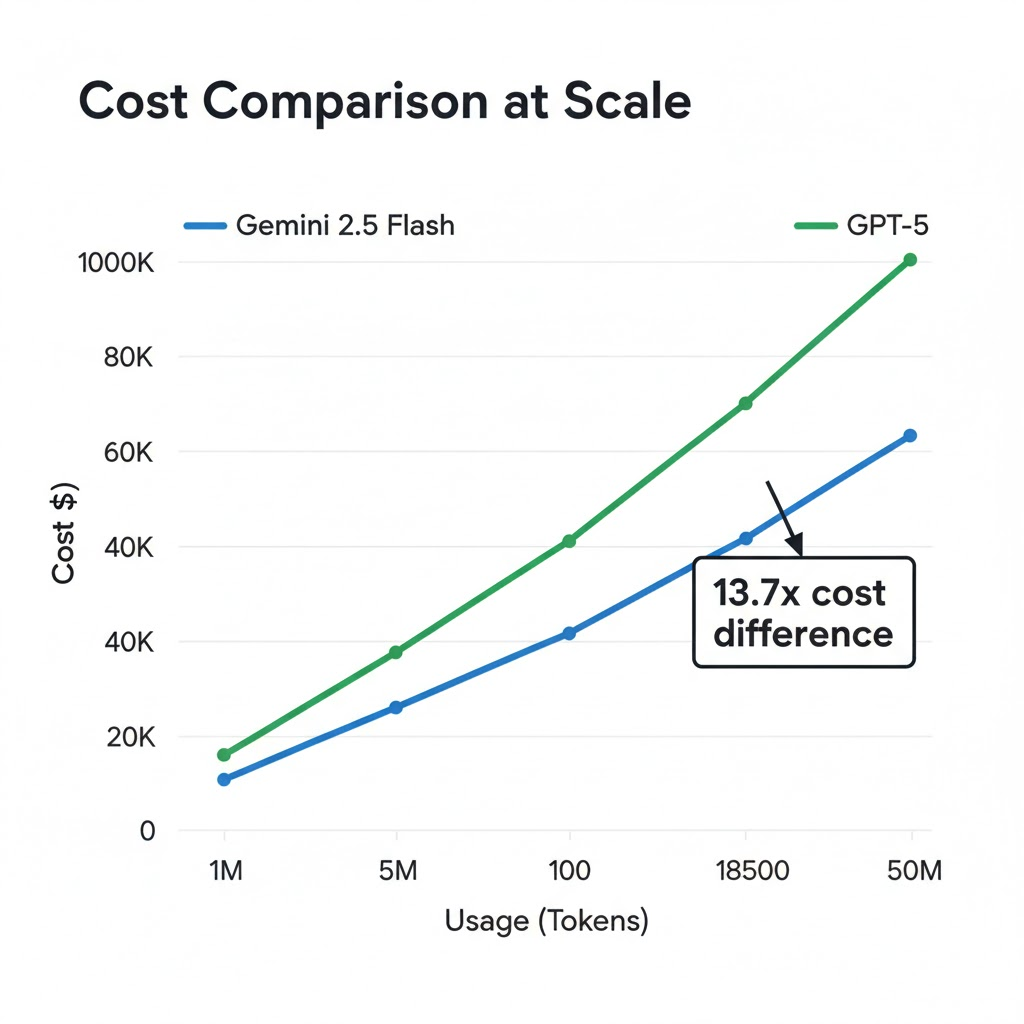
Gemini 2.5 Flash’s pricing advantage compounds dramatically at scale
When Speed Matters Most
Response latency creates different user experiences depending on application context. Understanding where speed provides genuine value versus where intelligence matters more determines optimal model selection.
Customer support chatbots benefit most from Flash’s speed advantage. Users asking product questions, troubleshooting steps, or account information expect immediate responses. Sub-3-second latency feels conversational and maintains engagement flow. Waiting 7-9 seconds for GPT-5 to think through a simple password reset question provides zero value. The quality difference rarely matters since most support queries require straightforward factual responses rather than complex reasoning.
Real-time coding assistants similarly prioritize speed. Developers using tools like AI-powered development environments expect near-instant code suggestions. A 2-second delay feels responsive and integrates seamlessly into development workflow. Waiting 5-7 seconds disrupts coding flow and creates friction. Flash provides code completions and explanations fast enough to feel natural rather than intrusive.
Interactive educational applications require low-latency responses to maintain learning momentum. Students asking questions or requesting explanations expect immediate feedback. The conversational nature of learning requires response times that feel natural rather than creating awkward pauses. Flash delivers adequate explanations quickly enough to support fluid educational interactions.
Content generation pipelines processing high volumes of requests prioritize both speed and cost. Generating thousands of product descriptions, social media posts, or email variations daily makes Flash’s combination of adequate quality and dramatically lower cost economically compelling. The quality gap matters less when human editors review outputs anyway, and processing throughput increases significantly with faster model responses.
Applications where speed matters less include research assistants performing deep analysis, creative writing tools where users expect thoughtful responses, complex problem-solving systems where correctness outweighs latency, and strategic planning tools where extended reasoning provides genuine value. GPT-5’s quality advantages justify longer wait times in these contexts because users explicitly want maximum intelligence rather than quick responses.
The pattern holds across domains. Applications optimizing for user experience and conversational flow benefit from Flash. Applications optimizing for output quality and correctness benefit from GPT-5. Understanding your application’s priorities determines which model delivers better overall value.
Real Limitations of Both
Gemini 2.5 Flash makes specific tradeoffs that appear in production use. The model occasionally produces overconfident responses to questions where uncertainty would be more appropriate. This manifests as definitive statements about ambiguous topics or failure to acknowledge knowledge limitations appropriately. GPT-5 more consistently hedges when dealing with uncertain information, though both models share the fundamental limitation of occasionally presenting plausible-sounding incorrect information as fact.
Flash’s reasoning shortcuts become apparent in multi-step problems requiring careful logical progression. The model sometimes jumps to conclusions without showing complete intermediate steps, leading to correct final answers arrived at through questionable logic. For educational tools where reasoning transparency matters or decision support systems requiring verifiable logic chains, this limitation creates problems. Users need to see the work, not just the answer.
Creative tasks expose Flash’s tendency toward generic outputs. When generating marketing copy, story narratives, or persuasive content, Flash produces competent but uninspired results. The model takes fewer creative risks and defaults to safer, more predictable language patterns. GPT-5 generates more distinctive voice and tone, takes bolder creative approaches, and produces more engaging content. This matters significantly for applications where output quality directly impacts business outcomes like user engagement, conversion rates, or brand perception.
GPT-5’s limitations center on latency and cost rather than capability gaps. The variable response time makes it unsuitable for applications requiring guaranteed sub-3-second responses. Building real-time interactive experiences requires predictable latency, and GPT-5’s intelligent routing introduces uncertainty. You can’t guarantee response times when the model might decide a query needs extended reasoning.
API costs prohibit use cases requiring extremely high token throughput unless economics justify premium pricing. Processing millions of routine queries daily becomes prohibitively expensive with GPT-5’s pricing. The model excels at complex problems where intelligence provides value, but applying that intelligence to simple queries wastes both money and time.
Both models share common limitations inherent to large language models. Neither reliably handles mathematical calculations beyond simple arithmetic without code execution tools. Neither maintains perfect factual accuracy; both occasionally hallucinate plausible-sounding incorrect information. Neither truly understands context the way humans do. They pattern-match based on training data rather than reasoning from first principles about how artificial intelligence systems actually work.
The multimodal capabilities of both models lag behind their text performance. Image understanding remains noticeably weaker than language comprehension. Both struggle with highly technical diagrams, subtle visual details, and spatial reasoning tasks. Video understanding capabilities exist but perform inconsistently. Audio processing works better than vision but still makes errors on accent recognition and background noise filtering.
Neither model provides real-time information without tool integration. Both require explicit search tools or API connections to access current data. The knowledge cutoff limitation affects both, though Google’s integration with search provides Gemini models with better access to current information when tools are enabled.
Which Model to Choose
The decision depends entirely on your application’s priorities and constraints. Clear patterns emerge from testing that guide model selection.
Choose Gemini 2.5 Flash when response latency directly impacts user experience and you’re processing high volumes of requests. The combination of 2-3x faster responses and 13x lower costs makes it the obvious choice for customer support chatbots, real-time coding assistants, high-volume content generation, interactive educational tools, and any application where conversational flow matters more than achieving maximum quality on every output.
Choose GPT-5 when output quality matters more than speed or cost. Creative writing applications, complex analysis tools, research assistants requiring reliable reasoning, decision support systems, advanced coding projects, and strategic planning tools all benefit from GPT-5’s superior intelligence. The longer response times become acceptable when users expect thoughtful, high-quality responses rather than conversational immediacy.
For applications with mixed requirements, consider hybrid approaches. Use Flash for initial responses requiring speed, then invoke GPT-5 selectively for complex queries detected through heuristics or user feedback. This architecture optimizes for both user experience and cost efficiency while providing maximum intelligence where it matters most. The implementation complexity increases, but the performance and cost benefits often justify the engineering investment.
Specific recommendations based on common use cases provide clearer guidance. Customer support systems should default to Gemini 2.5 Flash unless they regularly handle complex reasoning queries requiring multi-step problem solving. The speed and cost advantages outweigh minor quality differences for 80%+ of support interactions. Route edge cases requiring deep analysis to GPT-5 selectively.
Coding assistants benefit from Flash for code completion, simple explanations, and routine refactoring tasks. Switch to GPT-5 for architectural decisions, complex debugging requiring multiple reasoning steps, system design discussions, or situations where code quality and correctness matter more than delivery speed. The hybrid approach provides fast feedback for routine work while ensuring complex problems get appropriate analytical depth.
Content generation pipelines should use Flash for high-volume, editor-reviewed content where speed and cost matter most. Reserve GPT-5 for flagship content pieces where creative quality directly impacts business results like conversion rates, user engagement, or brand perception. The economics favor Flash for routine production while GPT-5 handles premium content requiring maximum creativity.
Research and analysis tools should prefer GPT-5 despite higher costs. The quality improvements in reasoning, accuracy, and analytical depth justify the premium for applications where correctness and thoroughness matter more than response speed. Wrong answers delivered quickly provide less value than correct answers delivered slowly.
Educational applications work well with Flash for quick explanations, factual queries, and routine tutoring interactions. Consider GPT-5 for complex problem-solving assistance where reasoning transparency and correctness are critical. Students benefit from seeing correct reasoning chains rather than quick but potentially flawed shortcuts.
FAQ
Q: Is Gemini 2.5 Flash faster than GPT-5 for all tasks?
A: Yes. Gemini 2.5 Flash maintains consistent 1.5-2.8 second response times across all task types, while GPT-5 ranges from 3.5 seconds for simple queries to 9+ seconds for complex reasoning tasks. Flash delivers 2-3x faster responses regardless of query complexity.
Q: Does GPT-5 produce better code than Gemini 2.5 Flash?
A: For most coding tasks, yes. GPT-5 scores 74.9% on SWE-bench Verified and 88% on Aider Polyglot coding benchmarks, producing more idiomatic code with better error handling. Gemini 2.5 Flash tops the WebDev Arena leaderboard for web development specifically but shows weaker performance across all programming domains.
Q: How much does Gemini 2.5 Flash cost compared to GPT-5?
A: Gemini 2.5 Flash costs $0.075 per million input tokens versus GPT-5’s $1.25, making Flash 16.7x cheaper for input and 33x cheaper for output tokens. A typical application processing 10 million tokens monthly costs approximately $1,350 with Flash compared to $18,500 with GPT-5.
Q: Which model is better for creative writing?
A: GPT-5 produces significantly better creative writing with more nuanced prose, stronger narrative consistency, more natural dialogue, and more creative risk-taking. Gemini 2.5 Flash generates competent but generic creative content. For applications where creative quality matters, GPT-5’s superiority justifies its slower response times and higher costs.
Q: Can I use both models in the same application?
A: Yes. Hybrid architectures work well, using Gemini 2.5 Flash for fast responses on routine queries and invoking GPT-5 selectively for complex problems requiring maximum intelligence. This optimizes for both user experience and cost efficiency while ensuring difficult problems get appropriate analytical depth.
Sources
- Google Gemini 2.5 Flash Model Page – Technical specifications, benchmark performance, thinking mode capabilities
- Google Blog: Gemini 2.5 Model Family Expands – Release details, general availability timeline, feature announcements
- Google Developers Blog: Gemini 2.5 Flash-Lite – Pricing details, performance metrics, use case examples
- Simon Willison: GPT-5 Key Characteristics – Unified system architecture, router functionality, system card analysis
- GPT-5 vs GPT-5 Pro Benchmark Comparison – GPQA, SWE-bench, AIME scores, comprehensive benchmark data
- InfoQ: OpenAI GPT-5 Release Analysis – Pricing structure, context window specifications, launch details
- GPT-5 Features Guide – Leanware – Detailed benchmark results, hallucination rates, multimodal performance
- GPT-5 vs GPT-5 Thinking Performance Analysis – Router functionality, token efficiency, error reduction metrics